
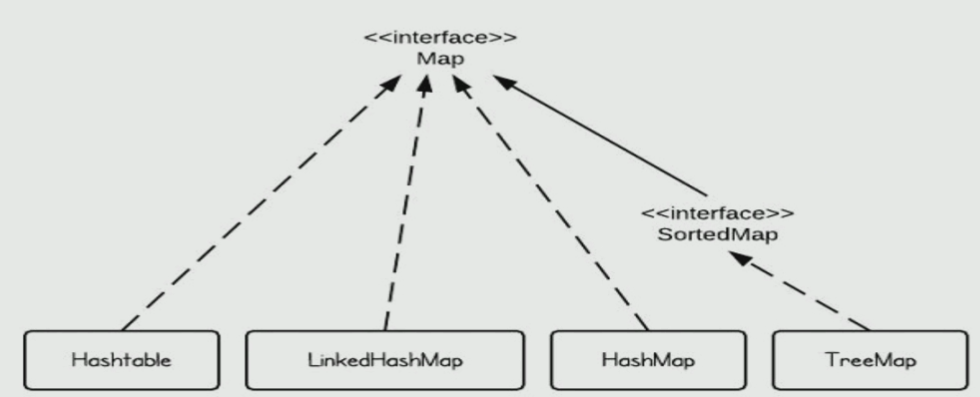
Map 映射
Map(key,value) key间值必须唯一,又称键值对,如下是 Java 几个主要的 Map 实现类。
HashMap 非同步 无序
1.非同步:
在并发环境下使用 HashMap 容易出现死循环
容量大于 总量负载因子 发生扩容时会出现环形链表
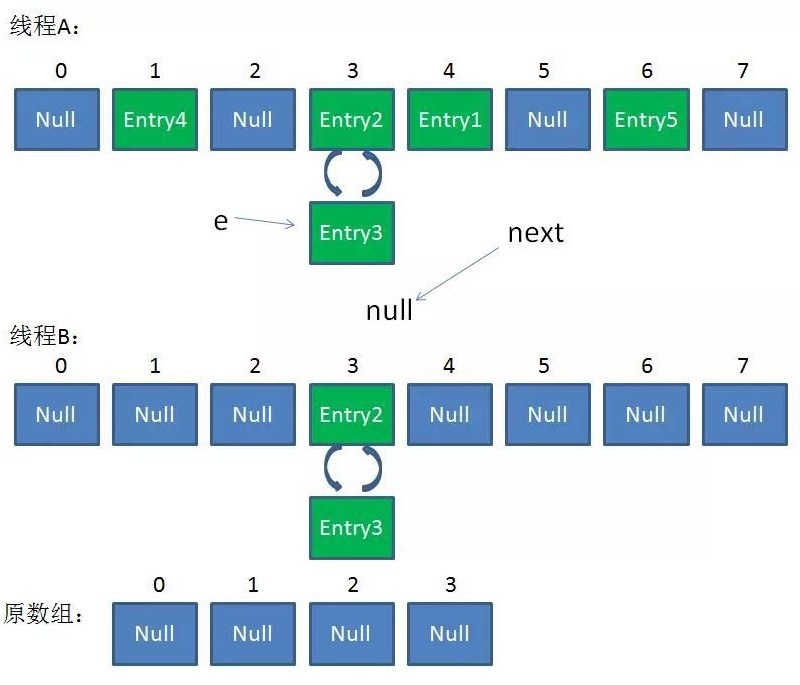
并发场景发生扩容,调用 resize() 方法里的 rehash() 时,容易出现环形链表
这样当获取一个不存在的 key 时,计算出的 index 正好是环形链表的下标时就会出现死循环,如下
final HashMap<String, String> map = new HashMap<String, String>(2);
for (int i = 0; i < 10000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
map.put(UUID.randomUUID().toString(), "");
}
}).start();
}
环形链表原因:
1.resize 是将 old 数据 copy 到新空间
2.多 Threads 同时 put,觉得内存不够,同时执行 resize
3.HashMap 扩容时,会改变链表中的元素的顺序,将元素从链表头部插入并发场景下出现死循环 多Threads同时put,同时调用了 resize ,可能导致循环链表,后面get的时候,会死循环
==>所以 HashMap,只能在单线程中,并且尽量的预设容量,尽可能的减少扩容。
2.数据结构
1.数组:连续内存,占内存严重,空间复杂度很大,二分查找O(1),寻址容易,插入和删除困难
2.链表:离散存储,占内存宽松,空间复杂度很小 O(N),寻址难,插入容易
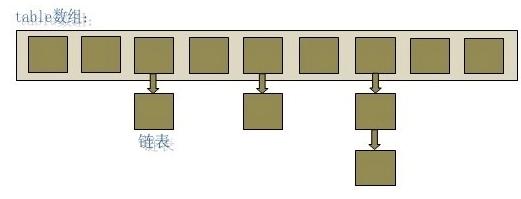
数组 + 链表:容量 capacity 默认16,负载因子 factor 默认 0.75f,元素数量 size
3.操作方法解析
1.put()
1.会将传入的 Key 做 hash 运算计算出 hashcode,然后根据数组长度取模计算出在数组中的 index 下标
2.计算中位运算比取模运算效率高的多,所以 HashMap 规定数组的长度为 2^n 。这样用 2^n - 1 做位运算
与取模效果一致,并且效率还要高出许多
3.数组的长度有限,所以难免会出现不同的 Key 通过运算得到的 index 相同,这种情况可以利用链表来解决,
HashMap 会在 table[index]处形成链表,采用头插法将数据插入到链表中
2.get()
将传入的 Key 计算出 index,如果该位置上是一个链表就需要遍历整个链表,通过 key.equals(k) 来找到对应的元素
3.iter 遍历方式
Iterator<Map.Entry<String, Integer>> entryIterator = map.entrySet().iterator();
while (entryIterator.hasNext()) {
Map.Entry<String, Integer> next = entryIterator.next();
System.out.println("key=" + next.getKey() + " value=" + next.getValue());
}
// 建议的方案 entry
Iterator<String> iterator = map.keySet().iterator();
while (iterator.hasNext()){
String key = iterator.next();
System.out.println("key=" + key + " value=" + map.get(key));
}
// 不太推荐先拿 key,再拿 value
map.forEach((key,value)->{
System.out.println("key=" + key + " value=" + value);
});
// 此方法 jdk1.8后使用,通过外层遍历table, 内层遍历链表或红黑树
LinkedHashMap
1.基础特性
HashMap 无序、LinkedHashMap 有序
底层是 HashMap,对 HashMap 做了扩展
由一个双向链表实现有序性,适合构建LRU缓存
// 构造方法
public LinkedHashMap() {
super();
accessOrder = false;
}
2.排序方式
根据写入顺序排序
根据访问顺序排序,此时每次 get 都会将访问的值移动到链表末尾,重复操作可得到按照访问顺序排序的链表
@Test
public void test(){
Map<String, Integer> map = new LinkedHashMap<String, Integer>();
map.put("1",1) ;
map.put("2",2) ;
map.put("3",3) ;
map.put("4",4) ;
map.put("5",5) ;
System.out.println(map.toString());
}
3.源码解析
1.Entry
继承于 HashMap 的 Entry,并新增了上下节点的指针,也就形成了双向链表
2.header 的成员变量
是这个双向链表的头结点
/**
* The head of the doubly linked list.
*/
private transient Entry<K,V> header;
/**
* The iteration ordering method for this linked hash map:
* <tt>true</tt> for access-order
* <tt>false</tt> for insertion-order.
*
* @serial
*/
private final boolean accessOrder; // true 访问,false 插入
// accessOrder 成员变量,默认是 false,默认按照插入顺序排序,为 true 时按照访问顺序排序
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
}
// 可如同如下方式调用
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
3.HashMap实现
public HashMap(int initialCapacity, float loadFactor) {
// initialCapacity 初始容量
// loadFactor 加载因子
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
//HashMap 只是定义了改方法,具体实现交给了 LinkedHashMap
init();
}
// 可以看到里面有一个空的 init(),具体是由 LinkedHashMap 来实现的:
@Override
void init() {
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
}// 对 header 进行了初始化
4.put() 方法
记得先看看 HashMap 的 put() 方法
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
//空实现,交给 LinkedHashMap 自己实现
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// LinkedHashMap 对其重写
addEntry(hash, key, value, i);
return null;
}
// LinkedHashMap 对其重写
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
// LinkedHashMap 对其重写
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
主体的实现都是借助于 HashMap 来完成的
对其中的 recordAccess(), addEntry(), createEntry() 进行了重写
//就是判断是否是根据访问顺序排序,如果是则需要将当前这个 Entry 移动到链表的末尾
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
//调用了 HashMap 的实现,并判断是否需要删除最少使用的 Entry(默认不删除)
void addEntry(int hash, K key, V value, int bucketIndex) {
super.addEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
}
}
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
//就多了这一步,将新增的 Entry 加入到 header 双向链表中
table[bucketIndex] = e;
e.addBefore(header);
size++;
}
//写入到双向链表中
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
5.get() 方法
LinkedHashMap 的 get() 方法也重写了
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
//多了一个判断是否是按照访问顺序排序,是则将当前的 Entry 移动到链表头部
e.recordAccess(this);
return e.value;
}
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
//删除
remove();
//添加到头部
addBefore(lm.header);
}
}
6.clear()
// 只需要把指针都指向自己即可,原本那些 Entry 没有引用之后就会被 JVM 自动回收
public void clear() {
super.clear();
header.before = header.after = header;
}
ConcurrentHashMap
1.CHM 出现的原因
1.HashMap 非同步、不安全原因了解下
2.HashTable 安全但效率低下,使用synchronized保证线程安全,
效率低:因为所有线程都竞争一把锁,竞争越激烈,效率越低
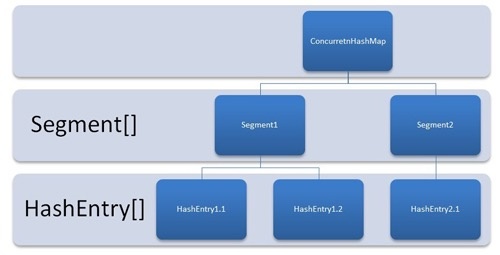
2.Segment 分段所 – JDK1.7 CHM 安全方案
1. 分段锁
一把锁变多把锁,分别锁容器中部分数据,当多线程访问容器中不同的数据段时,线程不存在锁竞争
1.数据**分段**,每段分一把锁
2.部分**跨段**的方法,如size()、containsValue(),需要锁定整个数据
这需要按顺序锁定所有段,操作结束,再按顺序释放所有锁
-- 这里不按顺序,容易出现死锁
-- 段数数组final的,成员变量也是final的
但仅仅将数组申明为final,并不保证数组成员也是final的,这需要实现上保证
==> 确保不出现死锁
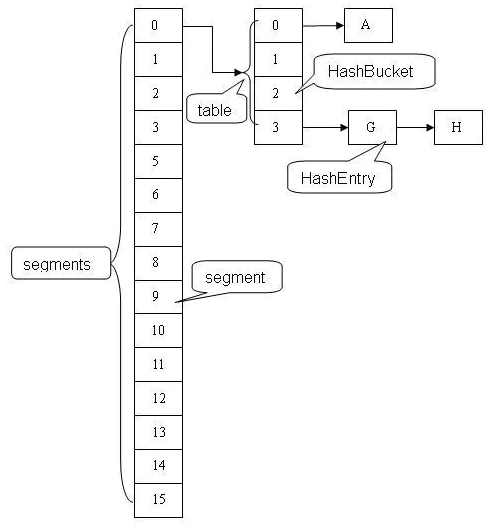
2.数据结构
Segment数组: 一种可重入非阻塞锁 ReentrantLock
一种数组和链表的结构 和 HashMap 相似
一个Segment包含一个 HashEntry数组,起守护作用 – 锁
每个HashEntry是一个链表结构的元素
HashEntry数组: 存储k-v数据
3.CHM 和 HashTable 区别
ConcurrentHashMap:并发散列映射表,它允许完全并发的读取,并且支持给定数量的并发更新
ConcurrentHashMap 是设计为非阻塞的。 在更新时会局部锁住某部分数据,但不会把整个表都锁住。 同步读取操作则是完全非阻塞的。 好处是在保证合理的同步前提下,效率很高。 坏处是严格来说读取操作不能保证反映最近的更新。HashTable:用一个全局的锁来同步不同线程间的并发访问,同一时间点,只能有一个线程持有锁,也就是说在同一时间点,只能有一个线程能访问容器,这虽然保证多线程间的安全并发访问,但同时也导致对容器的访问变成串行化的了
Hashtable的任何操作都会把整个表锁住,是阻塞的。 好处是总能获取最实时的更新 比如说线程A调用putAll写入大量数据,期间线程B调用get,线程B就会被阻塞,直到线程A完成putAll,因此线程B肯定能获取到线程A写入的完整数据。 坏处是所有调用都要排队,效率较低例如 线程 A 调用 putAll 写入大量数据,期间线程 B 调用 get,则只能 get 到目前为止已经顺利插入的部分数据。应该根据具体的应用场景选择合适的HashMap。
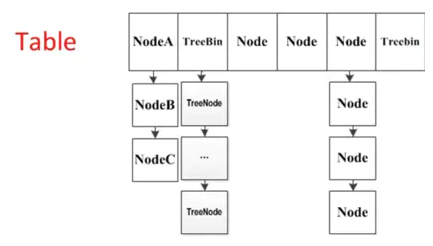
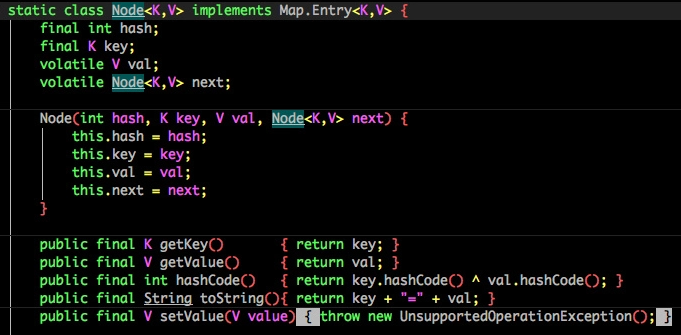
4.CAS + synchronized – JDK1.8 CHM 线程安全方案
- 放弃分段所
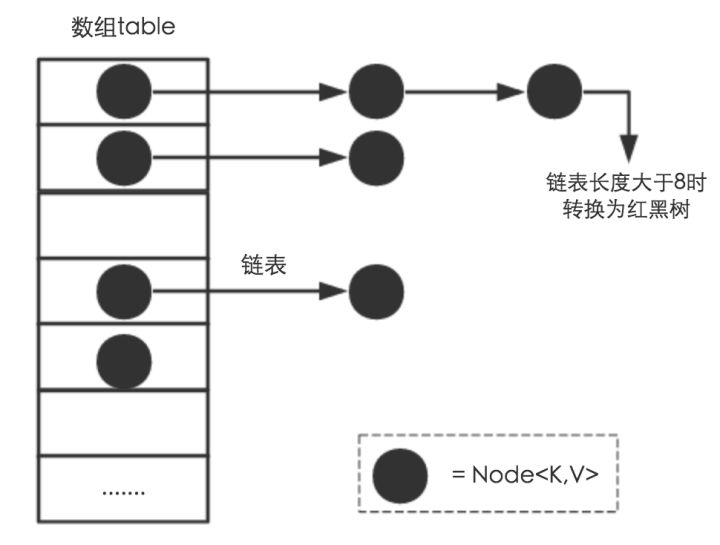
- 数据结构:【数组+链表+红黑树】
红黑树是一个特殊的平衡二叉树,查找的时间复杂度是 O(logn)
-- TreeNode
链表查找元素的时间复杂度为 O(n/2)
-- 普通Node
n越大 红黑树查找效率越好
刚开始用链表:普通Node空间小(TreeNode大概是普通Node2倍空间)
8Node用RB-Tree:查询效率高
链表长度到8,且 Map 容量 > 64,转化未RB-Tree,降低到6转回链表
通常情况下并不会转换,只有hash不均匀才会转换
Constructor 构造方法
//构造方法
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)//判断参数是否合法
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY ://最大为2^30
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
//根据参数调整table的大小
this.sizeCtl = cap;//获取容量
//ConcurrentHashMap在构造函数中只会初始化sizeCtl值,并不会直接初始化table
}
//调整table的大小
private static final int tableSizeFor(int c) {
//返回一个大于输入参数且最小的为2的n次幂的数。
int n = c - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
/*
tableSizeFor(int c) 的原理:将c最高位以下通过|=运算全部变成1,最后返回的时候,返回n+1;
eg:当输入为25的时候,n等于24,转成二进制为1100,右移1位为0110,将1100与0110进行或("|")操作,得到1110。
接下来右移两位得11,再进行或操作得1111,接下来操作n的值就不会变化了。
最后返回的时候,返回n+1,也就是10000,十进制为32。
按照这种逻辑得到2的n次幂的数
那么为什么要先-1再+1呢?输入若是为0,那么不论怎么操作,n还是0,但是HashMap的容量只有大于0时才有意义
*/
Table 初始化
table 初始化操作会延缓到第一次 put 行为。但是 put 是可以并发执行的,那么是如何实现table只初始化一次的?
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)//判断table还未初始化
tab = initTable();//初始化table
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
...省略一部分源码
}
}
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// 如果一个线程发现sizeCtl<0,意味着另外的线程执行CAS操作成功,
// 当前线程只需要让出cpu时间片,
// 由于sizeCtl是volatile的,保证了顺序性和可见性
if ((sc = sizeCtl) < 0)//sc保存了sizeCtl的值
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSetInt(this, SIZECTL, sc, -1)) {//cas操作判断并置为-1
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
//DEFAULT_CAPACITY = 16,若没有参数则大小默认为16
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
put() 方法
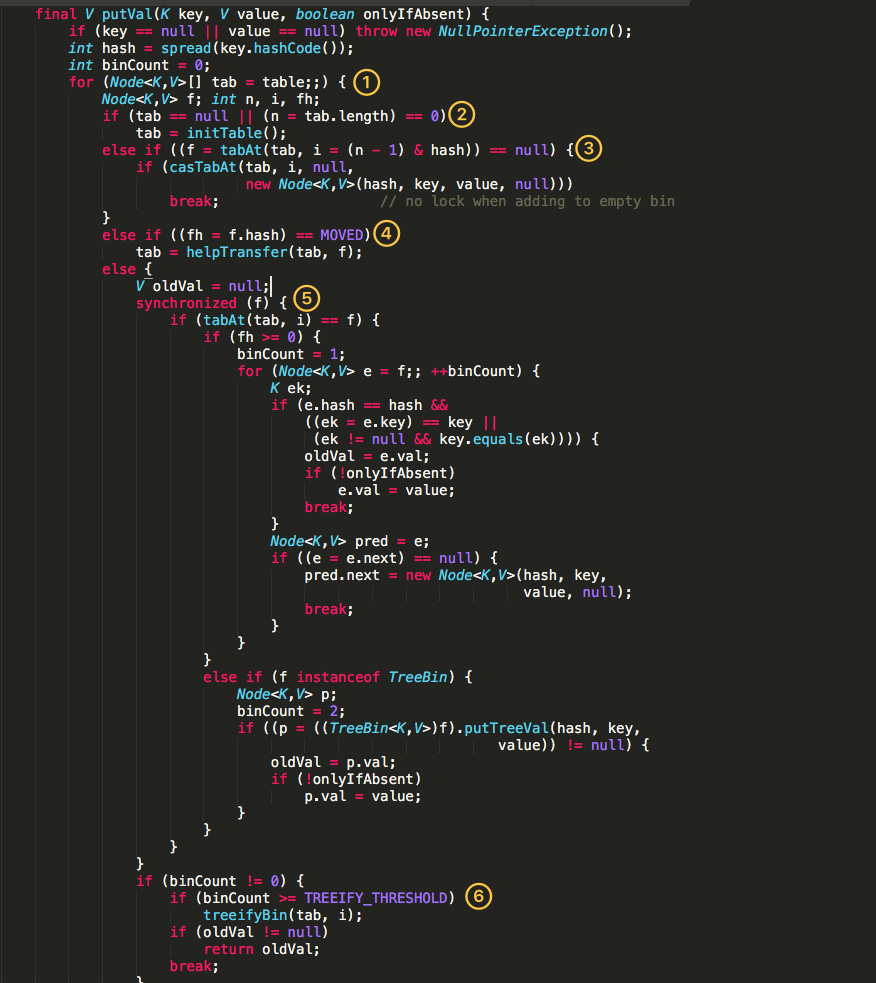
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());//哈希算法
int binCount = 0;
for (Node<K,V>[] tab = table;;) {//无限循环,确保插入成功
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)//表为空或表长度为0
tab = initTable();//初始化表
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//i = (n - 1) & hash为索引值,查找该元素,
//如果为null,说明第一次插入
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)//MOVED=-1;当前正在扩容,一起进行扩容操作
tab = helpTransfer(tab, f);
else if (onlyIfAbsent && fh == hash && // check first node
((fk = f.key) == key || fk != null && key.equals(fk)) &&
(fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {//其他情况加锁同步
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
//哈希算法
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
//保证拿到最新的数据
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectAcquire(tab, ((long)i << ASHIFT) + ABASE);
}
//CAS操作插入节点,比较数组下标为i的节点是否为c,若是,用v交换,否则不操作。
//如果CAS成功,表示插入成功,结束循环进行addCount(1L, binCount)看是否需要扩容
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSetObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
Table 扩容
able 容量不足的时候,即table的元素数量达到容量阈值sizeCtl,需要对table进行扩容。 整个扩容分为两部分:
1.构建一个nextTable,大小为table的两倍。
2.把table的数据复制到nextTable中。
这两个过程在单线程下实现很简单
但是ConcurrentHashMap是支持并发插入的,扩容操作自然也会有并发的出现,这种情况下,
第二步可以支持节点的并发复制,这样性能自然提升不少,但实现的复杂度也上升了一个台阶
- 第一步,构建nextTable,毫无疑问,这个过程只能只有单个线程进行nextTable的初始化.
private final void addCount(long x, int check) {
... 省略部分代码
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {// sc < 0 表明此时有别的线程正在进行扩容
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
// 不满足前面5个条件时,尝试参与此次扩容,把正在执行transfer任务的线程数加1,+2代表有1个,+1代表有0个
transfer(tab, nt);
}
//试着让自己成为第一个执行transfer任务的线程
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);// 去执行transfer任务
s = sumCount();// 重新计数,判断是否需要开启下一轮扩容
}
}
}
节点从table移动到nextTable,大体思想是遍历、复制的过程。
遍历过所有的节点以后就完成了复制工作,把table指向nextTable,并更新sizeCtl为新数组大小的0.75倍 ,扩容完成
get()
判断table是否为空,如果为空,直接返回null
计算key的hash值,并获取指定table中指定位置的Node节点,通过遍历链表或则树结构找到对应的节点,返回value值
源码:
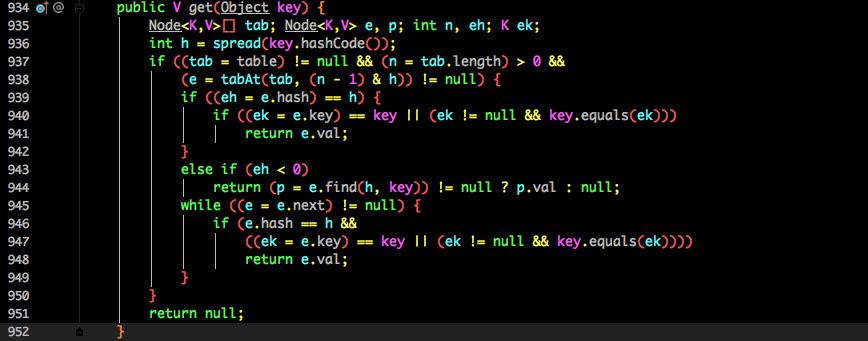
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
参考:
文档信息
- 本文作者:jiushun.cheng
- 本文链接:https://minipa.github.io/2016/06/26/java-data/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)