
1.Java 系统内部锁优化 ABEC
1.内部锁 synchronized JVM 管理锁 不会出现锁泄漏
2.显示锁 ReentrantLock等
- 锁消除(Lock Elision) JIT 编译器对内部锁的优化
逃逸:方法体之外引用方法内的对象
方法执行完后,此方法内对象,由于被方法外引用,无法gc回收–逃逸
逃逸分析 :
Java JIT 会通过逃逸分析的方式,去分析加锁的代码段/共享资源,
是否被一个或者多个线程使用,或者等待被使用
通过分析证实,只被一个线程访问,在编译这个代码段的时候就不生成 Synchronized 关键字,仅仅生成代码对应的机器码
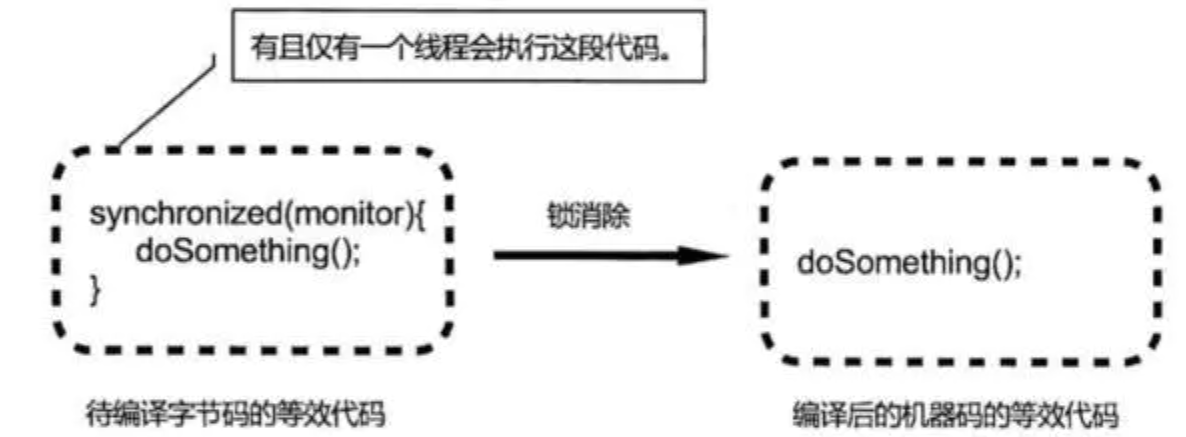
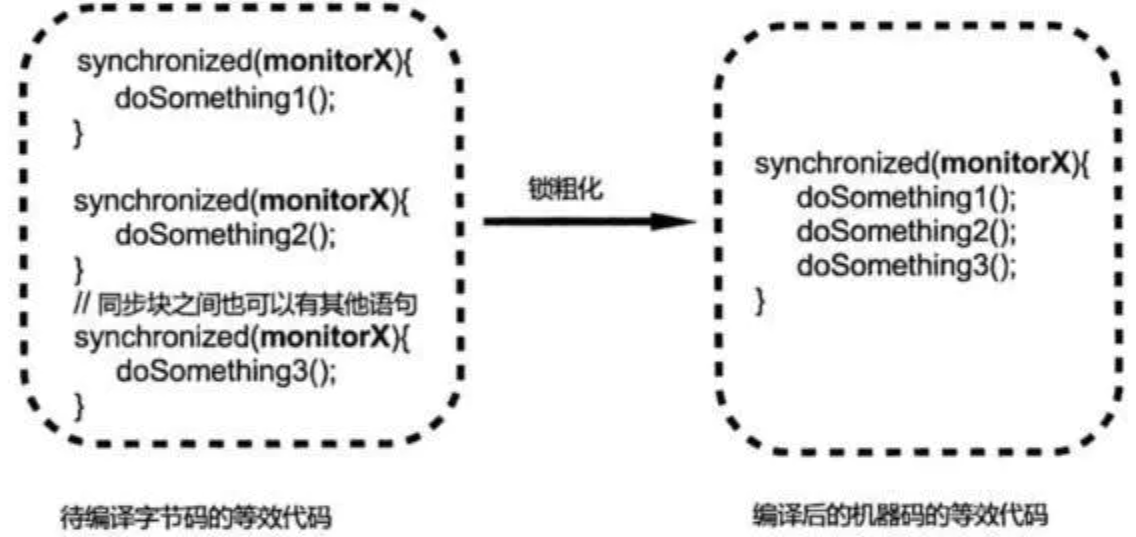
- 锁粗化(Lock Coarsening)
JIT 编译器对内部锁具体实现的优化
假设有几个在程序上相邻的同步块(代码段/共享资源)上,每个同步块使用的是同一个锁实例。
那么 JIT 会在编译的时候将这些同步块合并成一个大同步块,并且使用同一个锁实例。这样避免一个线程反复申请/释放锁
- 偏向锁(Biased Locking) 偏向于第一个访问锁的线程
偏向锁只能在单个线程反复持有该锁的时候起效,为了避免相同线程获取同一个锁时,产生的线程切换,以及同步操作。
从实现机制上讲, 每个偏向锁都关联一个计数器和一个占有线程
最开始没有线程占有的时候,计数器为 0,锁被认为是 unheld 状态。当有线程请求 unheld 锁时,JVM 记录锁的拥有者,并把锁的请求计数加 1。如果同一线程再次请求锁时,计数器就会增加 1,当线程退出 Syncronized 时,计数器减 1,当计数器为 0 时,锁被释放
为了完成上述实现,锁对象中有个 ThreadId 字段。第一次获取锁之前,该字段是空的。持有锁的线程,会将自身的 ThreadId 写入到锁的 ThreadId 中。下次有线程获取锁时,先检查自身 ThreadId 是否和偏向锁保存的 ThreadId 一致。如果一致,则认为当前线程已经获取了锁,不需再次获取锁。偏向锁默认是开启的
如果要关闭这个特性,可以在 Java 程序的启动命令行中添加虚拟机参数“-XX:-UseBiasedLocks”
- 适应锁(Adaptive Locking)
当一个线程持申请锁时,该锁正在被其他线程持有。
那么申请锁的线程会进入等待,等待的线程会被暂停,暂停的线程会产生上下文切换
由于上下文切换是比较消耗系统资源的,所以这种暂停线程的方式比较适合线程处理时间较长的情况
前面一个线程执行的时间较长,才能弥补后面等待线程上下文切换的消耗
如果说线程执行较短,那么也可以采取忙等(Busy Wait)的状态
这种方式不会暂停线程,通过代码中的 while 循环检查锁是否被释放,一旦释放就持有锁的执行权
这种方式虽然不会带来上下文的切换,但是会消耗 CPU 的资源
为了综合较长和较短两种线程等待模式,JVM 会根据运行过程中收集到的信息来判断,锁持有时间是较长时间或者较短时间。然后再采取线程暂停或忙等的策略
2.Java 代码中锁优化
锁的开销主要是在争用锁上,当多线程对共享资源进行访问时,会出现线程等待。
即便是使用内存屏障,也会导致冲刷写缓冲器,清空无效化队列等开销。
为了降低这种开销,通常可以从几个方面入手,
例如:
减少线程申请锁的频率(减少临界区)
减少线程持有锁的时间长度(减小锁颗粒)以及
多线程的设计模式
- 缩小临界区的范围
当共享资源需要被多线程访问时,会将共享资源或者代码段放到临界区中。
如果在代码书写中减少临界区的长度,就可以减少锁被持有的时间,从而降低锁被征用的概率,达到减少锁开销的目的。
尽量避免对一个方法进行加锁同步,可以只针对方法中的需要同步资源/变量进行同步,其他的代码段不放到 Synchronzied 中,减少临界区的范围。
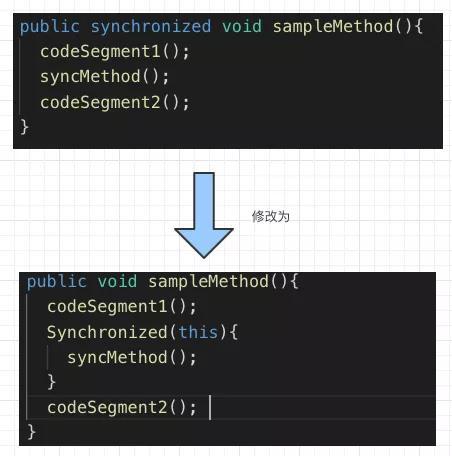
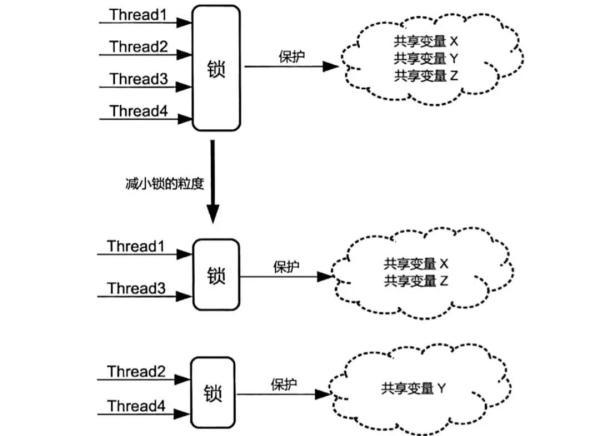
- 减小锁的颗粒度
减小锁的颗粒度可以降低锁的申请频率,从而减小锁被争用的概率。
其中一种常见的方法就是将一个颗粒度较粗的锁拆分成颗粒度较细的锁
假设有一个类 ServerStatus,里面包含了四个方法:
addUser
addQuery
removeUser
removeQuery
如果分别在每个方法加上 Synchronized
在一个线程访问其中任意一个方法的时候,将锁住 ServerStatus,此时其他线程都无法访问另外三个方法,从而进入等待
如果只针对每个方法内部操作的对象加锁,例如:addUser 和 removeUser 方法针对 users 对象加锁;addQuery 和 removeQuery 方法针对 queries 对象加锁
假设,当一个线程池调用 addUser 方法的时候,只会锁住 user 对象
另外一个线程是可以执行 addQuery 和 removeQuery 方法的
并不会因为锁住整个对象而进入等待
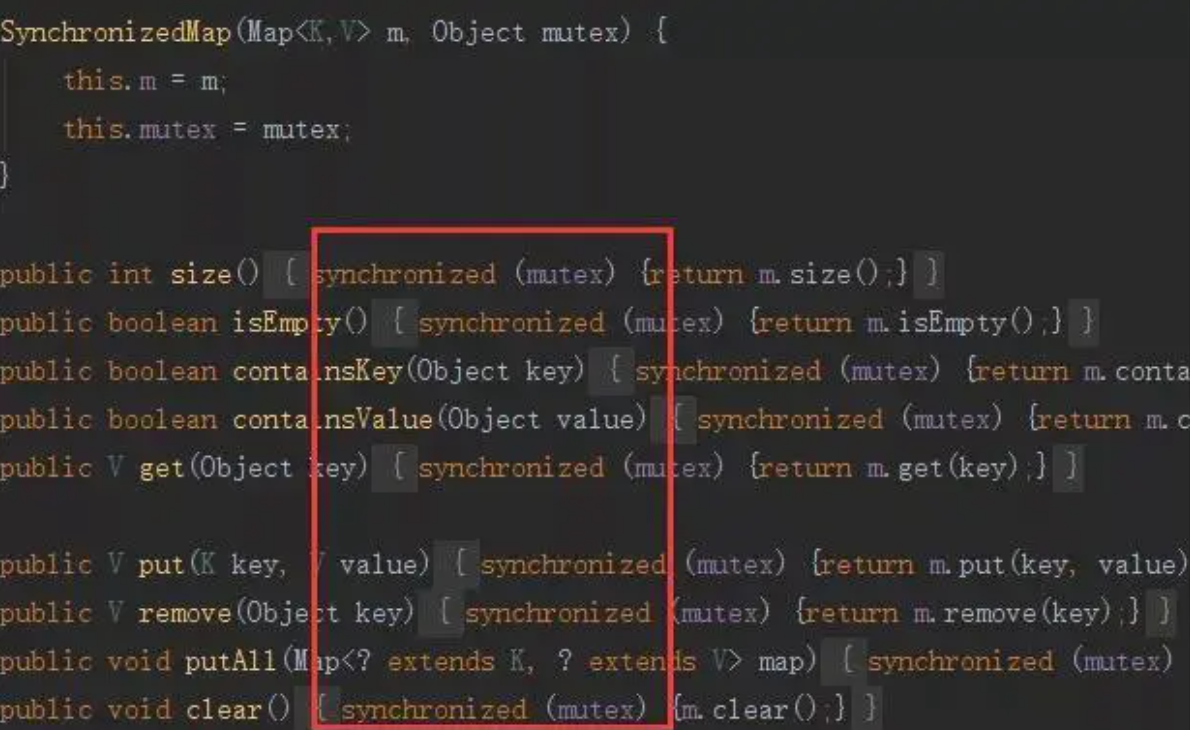
JDK 内置的 ConcurrentHashMap 与 SynchronizedMap 就使用了类似的设计, 针对不同的方法中使用的对象进行锁定
3.线程池优化
- 基本概念与原理
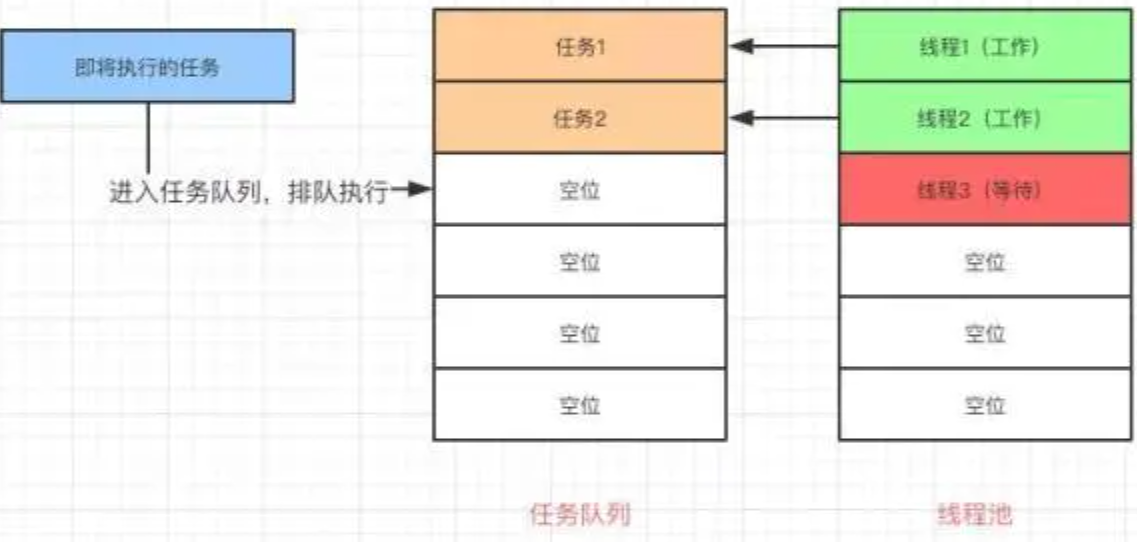
Java 线程池会生成一个队列,要执行的任务会被提交到这个队列中,有一定数量的线程会在队列中取任务,然后执行。
任务执行完毕以后,线程会返回任务队列,等待其他任务并执行。
线程池中有一定数量的线程随时待命。
由于生成和维持这些线程是需要耗费资源的,维持太多或者太少的线程都会对系统运行效率造成影响,因此对线程池优化是有意义的
【corePoolSize】线程池的基本大小,无论是否有任务需要执行,线程池中线程的个数
只有在工作队列占满的情况下,才会创建超出这个数量的线程
【maximumPoolSize】线程池中允许存在的最大线程数
【poolSize】线程池中线程的数量
- 当提交任务需要流程池处理时,会经过以下判断
pool<core 创建Thread并执行任务
pool>=core and blockQueue未满,将任务提交到阻塞队列排队等候处理
pool>=core and blockQueue满
and pool<max 创建Thread并处理
and pool=max 执行拒绝策略
1.corePoolSize
太小 ==> 吞吐量不足,新任务排队或被拒绝
太大 ==> 耗尽 CPU 和 内存
CPU 密集型:尽可能小的线程 如 CPU+1 线程
IO 密集型:尽可能多的线程,IO不占用CPU,如2*CPU+1
==> 实际环境中需要测试
最佳线程数目=((线程等待时间 + 线程CPU时间) / 线程CPU时间 ) * CPU数目
最佳线程数目= (线程等待时间与线程CPU时间之比 + 1) * CPU数目
==> 线程等待时间所占比例越高,需要越多线程
若任务对其他系统资源有依赖,如任务依赖数据库返回的结果(IO 操作)。其等待时间越长,CPU 空闲时间就越长,那么线程数量应该越大,才能更好的利用 CPU。因此在 IO 优化中发现一个估算公式:
最佳线程数目=((线程等待时间 + 线程CPU时间) / 线程CPU时间 ) * CPU数目
将公式进一步化简,得到:
最佳线程数目= (线程等待时间与线程CPU时间之比 + 1) * CPU数目
因此得到结论:线程等待时间所占比例越高,需要越多线程。线程 CPU 时间所占比例越高,需要越少线程。从另外一个角度验证上面对 IO 密集型(线程等待时间占比高)和 CPU 密集型(CPU 时间占比高)设置线程池大小的想法
参考:
文档信息
- 本文作者:jiushun.cheng
- 本文链接:https://minipa.github.io/2016/07/08/thread-youhua/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)