
1.Redis
1.Redis 协议
出发点 ==> 简单的实现,快速地被计算机解析,简单得可以能被人工解析 doc
基于客户端/服务端 B/C 的 TCP 服务
key-value store、NoSQL database
复制 (replication)
LUA脚本 (Lua scripting)
LRU驱动事件 (LRU eviction)
事务(transactions) -- C
不同级别的 磁盘持久化(persistence) -- P
并通过 Redis哨兵(Sentinel)和 自动分区(Cluster)
提供高可用性(high availability) -- A
2.用途
1.DataBase 内存数据库
2.Message Broker 消息中间件 – 不同进程 通信
3.Cache 分布式缓存 – 不同进程 共享资源
3.缓存原因
1.对数据库改动很少,高频次调用,会增加数据库的压力(查询多,修改少)
2.从缓存获取数据,比数据库快很多
3.直接访问一个存在的对象,比创建一个对象快很多
4.缓存架构发展很快,本地缓存、集群缓存、分布式缓存(数据网格)
5.分布式系统一般有 一级缓存、二级缓存、甚至三级缓存
6.需要有缓存穿透、缓存雪崩的解决方案
import org.springframework.cache.annotation.Cacheable;
// 添加缓存
@Cacheable(cacheNames = "demo-info", key = "#name")
// 移除缓存
@CacheEvict(cacheNames = "demo-info", key = "#name")
4.Redis 和 其它内存数据库
1.Redis 有复杂数据结构 和 原子操作,Redis基于基本数据结构,并对程序员透明,无需额外抽象。
2.Redis可序列化到磁盘,高速读写需要权衡内存
100万个键值对(键是0到999999值是字符串“hello world”)在我的32位的Mac笔记本上 用了100MB
2.Reids 和 Mysql
1.Redis 比 Mysql 快的原因
1)内存读取比硬盘读取快 100多倍
mysql [磁盘存储] 是全局扫描,或索引查找,涉及磁盘查找
redis [内存存储] 根据内存位置直接取出
1)DDR4 2400 速度是 2,4000M/S左右
2)机械硬盘 速度就 100/200M/S
2)Redis K-V 数据查找时间复杂度更低
redis k-v 格式 时间复杂度 O(1) 常数阶
mysql B+Tree 时间复杂度 O(logn) 对数阶
Redis 会比 mysql 快一点点
3)redis 单线程 多路复用IO
- 单线程 避免线程切换开销
- 多路复用IO 避免IO等待开销
在多核处理器**下提高处理器效率,可以对数据进行分区,每个CPU处理不同数据
2.redis 性能瓶颈
redis性能瓶颈存在于网络带宽
Redis 更喜欢大缓存快速 CPU, 而不是多核
在多核 CPU 服务器上面,Redis 的性能还依赖 NUMA 配置和处理器绑定位置。最明显的影响是 redis-benchmark 会随机使用CPU内核。
为了获得精准的结果,需要使用固定处理器工具(在 Linux 上可以使用 taskset)。
最有效的办法是将客户端和服务端分离到两个不同的 CPU 来高校使用三级缓存
3.硬盘 和 内存数据库
- 硬盘数据库
1.mysql是持久化存储,一定会涉及到 IO,用 memcached(mc) 优化
访问mc,如果未命中,就去访问mysql,之后复制数据到mc一部分。
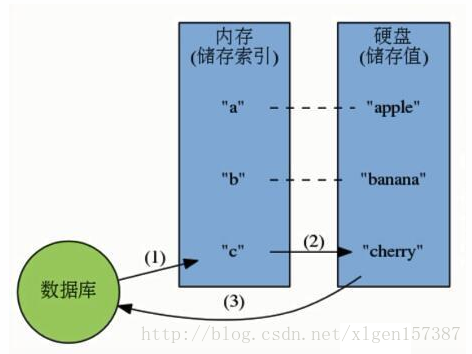
- 内存数据库,不受I/O限制
2.redis mc 都是缓存,mc 只提供简单的数据结构,所以mc慢慢舍弃了
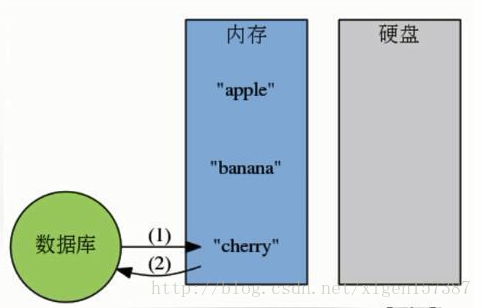
3.Redis快速的原因:
1)基于内存,好多数据结构查找时间复杂度都是 o(1)
2)数据结构简单,操作简单,是专门设计过的
3)单线程,避免了上下文切换和竞争条件,不存在多进程/多线程切换消耗CPU,不用考虑锁问题
4)多路复用I/O,非阻塞I/O
5)底层模型不同,直接构建了自己的 VM 机制,一般调用系统函数会浪费时间去移动和请求
多路复用 IO模型
利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程
采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求,(尽量减少网络 IO 的时间消耗),
且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈。
主要由以上几点造就了 Redis 具有很高的吞吐量
4.其它模型
1、单进程多线程模型:MySQL、Memcached、Oracle(Windows版本);
2、多进程模型:Oracle(Linux版本);
3、Nginx有两类进程,一类称为Master进程(相当于管理进程),另一类称为Worker进程(实际工作进程)。启动方式有两种:
(1)单进程启动:此时系统中仅有一个进程,该进程既充当Master进程的角色,也充当 Worker 进程的角色
(2)多进程启动:此时系统有且仅有一个 Master 进程,至少有一个Worker进程工作
(3)Master进程主要进行一些全局性的初始化工作和管理 Worker 的工作;
事件处理是在Worker中进行的。
5.Redis 存储方案
1.存储过程 – set
1.从 redisDb 当中找到 dict,每个db就一个 dict而已
2.从dict当中选择具体的dictht对象
3.首先根据key计算hash桶的位置,也就是index
新建一个DictEntry对象用于保存key/value,将新增的entry挂到dictht的table对应的hash桶当中,每次保存到挂链的头部
dictSetKey的宏保存key
dictSetVal的宏保存value
/* High level Set operation. This function can be used in order to set
* a key, whatever it was existing or not, to a new object.
*
* 高层次的 SET 操作函数。
*
* 这个函数可以在不管键 key 是否存在的情况下,将它和 val 关联起来。
*
* 1) The ref count of the value object is incremented.
* 值对象的引用计数会被增加
*
* 2) clients WATCHing for the destination key notified.
* 监视键 key 的客户端会收到键已经被修改的通知
*
* 3) The expire time of the key is reset (the key is made persistent).
* 键的过期时间会被移除(键变为持久的)
*/
void setKey(redisDb *db, robj *key, robj *val) {
// 添加或覆写数据库中的键值对
if (lookupKeyWrite(db,key) == NULL) {
dbAdd(db,key,val);
} else {
dbOverwrite(db,key,val);
}
incrRefCount(val);
// 移除键的过期时间
removeExpire(db,key);
// 发送键修改通知
signalModifiedKey(db,key);
}
/* Add the key to the DB. It's up to the caller to increment the reference
* counter of the value if needed.
*
* 尝试将键值对 key 和 val 添加到数据库中。
*
* 调用者负责对 key 和 val 的引用计数进行增加。
*
* The program is aborted if the key already exists.
*
* 程序在键已经存在时会停止。
*/
void dbAdd(redisDb *db, robj *key, robj *val) {
// 复制键名
sds copy = sdsdup(key->ptr);
// 尝试添加键值对
int retval = dictAdd(db->dict, copy, val);
// 如果键已经存在,那么停止
redisAssertWithInfo(NULL,key,retval == REDIS_OK);
// 如果开启了集群模式,那么将键保存到槽里面
if (server.cluster_enabled) slotToKeyAdd(key);
}
/* Add an element to the target hash table */
/*
* 尝试将给定键值对添加到字典中
*
* 只有给定键 key 不存在于字典时,添加操作才会成功
*
* 添加成功返回 DICT_OK ,失败返回 DICT_ERR
*
* 最坏 T = O(N) ,平滩 O(1)
*/
int dictAdd(dict *d, void *key, void *val)
{
// 尝试添加键到字典,并返回包含了这个键的新哈希节点
// T = O(N)
dictEntry *entry = dictAddRaw(d,key);
// 键已存在,添加失败
if (!entry) return DICT_ERR;
// 键不存在,设置节点的值
// T = O(1)
dictSetVal(d, entry, val);
// 添加成功
return DICT_OK;
}
/*
* 尝试将键插入到字典中
*
* 如果键已经在字典存在,那么返回 NULL
*
* 如果键不存在,那么程序创建新的哈希节点,
* 将节点和键关联,并插入到字典,然后返回节点本身。
*
* T = O(N)
*/
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
// 如果条件允许的话,进行单步 rehash
// T = O(1)
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
// 计算键在哈希表中的索引值
// 如果值为 -1 ,那么表示键已经存在
// T = O(N)
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
// T = O(1)
/* Allocate the memory and store the new entry */
// 如果字典正在 rehash ,那么将新键添加到 1 号哈希表
// 否则,将新键添加到 0 号哈希表
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
// 为新节点分配空间
entry = zmalloc(sizeof(*entry));
// 将新节点插入到链表表头
entry->next = ht->table[index];
ht->table[index] = entry;
// 更新哈希表已使用节点数量
ht->used++;
/* Set the hash entry fields. */
// 设置新节点的键
// T = O(1)
dictSetKey(d, entry, key);
return entry;
}
// 设置给定字典节点的键
#define dictSetKey(d, entry, _key_) do { \
if ((d)->type->keyDup) \
entry->key = (d)->type->keyDup((d)->privdata, _key_); \
else \
entry->key = (_key_); \
} while(0)
// 设置给定字典节点的值
#define dictSetVal(d, entry, _val_) do { \
if ((d)->type->valDup) \
entry->v.val = (d)->type->valDup((d)->privdata, _val_); \
else \
entry->v.val = (_val_); \
} while(0)
2.存储结构
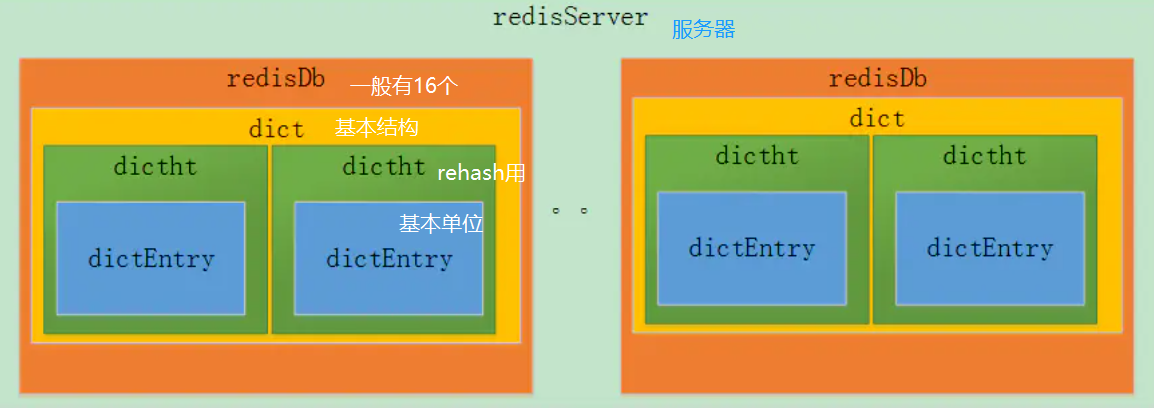
- redisServer 内部包含着 redisDb *db的数组元素,只是用指针体现而已
struct redisServer {
/* General */
// 配置文件的绝对路径
char *configfile; /* Absolute config file path, or NULL */
// serverCron() 每秒调用的次数
int hz; /* serverCron() calls frequency in hertz */
// 数据库
redisDb *db;
// 省略很多其他属性
}
- redisDb内部包含着dict *dict和dict *expires,用于存储数据和过期事件
typedef struct redisDb {
// 数据库键空间,保存着数据库中的所有键值对
dict *dict; /* The keyspace for this DB */
// 键的过期时间,字典的键为键,字典的值为过期事件 UNIX 时间戳
dict *expires; /* Timeout of keys with a timeout set */
// 正处于阻塞状态的键
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) */
// 可以解除阻塞的键
dict *ready_keys; /* Blocked keys that received a PUSH */
// 正在被 WATCH 命令监视的键
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
struct evictionPoolEntry *eviction_pool; /* Eviction pool of keys */
// 数据库号码
int id; /* Database ID */
// 数据库的键的平均 TTL ,统计信息
long long avg_ttl; /* Average TTL, just for stats */
} redisDb;
- dict 内部包含 dictht ht[2],是存储数据的对象,之所以有两个元素是为了扩容方便
/*
* 字典
*/
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 目前正在运行的安全迭代器的数量
int iterators; /* number of iterators currently running */
} dict;
- 真正保存数据的核心数据结构, dictEntry table可以理解为hash的桶,通过挂链法解决冲突
/*
* 哈希表
*
* 每个字典都使用两个哈希表,从而实现渐进式 rehash
*/
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
- 存储数据的单个节点,包含key和value。保存我们存储在redis的数据
/*
* 哈希表节点
*/
typedef struct set {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
参考:
https://www.jianshu.com/p/8299aea62ab8 挺好的Blog http://redisdoc.com/topic/protocol.html#id3 官方
http://www.redis.cn/
https://github.com/redis
文档信息
- 本文作者:jiushun.cheng
- 本文链接:https://minipa.github.io/2016/07/19/redis-info/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)