
1.Redis 值类型
SDS 二进制安全字符串
- List 按插入顺序排序的字符串元素的集合 LinkedList 链表
Set 不重复且无序的字符串元素集合
Sorted Set 不重复有序元素集合,跳跃表实现有序,每个元素都关联到一个score的浮动值,以此进行排序,且跳跃表可以起到检索的作用。如:给我前10 或 后10个元素
Hash: filed-value组成的map,两者均是字符串
Bit array: 特殊命令可以将string当作一系列bits处理,可设置和清除单独的bits,数出所有设置为1的bits数量,找到最前的被设为 1 或 0 的 bit等等。
- HyperLogLogs: 估计一个set中元素数量的概率性的数据结构
2.Redis Key
1.key值是二进制安全 ==> 可用任何二进制序列作为key,包括图形jpg
2.可以是空字符串
1)太长,耗内存、查找键值成本高
- 2)太短,”u:1000:pwd”来代替”user:1000:password” 不易读
- 3)坚持一种 key模式,如:”object-type
 field”,”user:1000:password”
field”,”user:1000:password”
1.向聚合类型中添加元素时,如目标key不存在,就先创建空的聚合数据类型
> del mylist
(integer) 1
> lpush mylist 1 2 3
(integer) 3
2.从聚合类型移除元素,如果值仍然时空的,key自动被销毁
> lpush mylist 1 2 3
(integer) 3
> exists mylist
(integer) 1
> lpop mylist
"3"
> lpop mylist
"2"
> lpop mylist
"1"
> exists mylist
(integer) 0
// 所有的元素被弹出之后, key 不复存在
3.对一个空key调用一个只读命令,如:LLEN 或删除一个元素的命令,将从事产生相同的效果 –> 该结果和对一个空的聚合类型做同个操作的结果是一样的
以上原则适用于: [list、sets、sorted sets、hashes 等含多个元素的 Redis 数据类型]
- Rdis 命令惯例
1."x" existed 存在才操作成功
2."nx" not existed 不存在
3."b" blocked 阻塞式操作
4."store" 保存结果到 destination5."count|card|length" 获取成员数
6."inter|union|diff" 交 并 差
7."lex" 字典qu'jian
3 基本数据结构
3.1 s – SDS Simple Dynamic String

2.SDS 与 c String
1.高效length计算:SDS- O(1) 记录 String-O(N) 遍历
2.高效 Append操作:修改时,动态扩展内存空间,避免了c String中直接修改字符串–数据溢出,减少内存重分配次数
1)SDS空间预分配
2)惰性空间释放,用free记录释放的字节数量,将来使用,并没立马收回多余空间
3.API二进制安全:
SDS API 以处理二进制方式处理 SDS 存放在 buff 里的数据
程序不会对其中任何数据做修改、过滤或假设4.兼容部分c字符串函数:在末尾保存一个空字符 ‘\0’
是为了使用一些c字符串函数库,避免不必要的代码重复 如 字符串对比函数: /strcasecmp函数
3.用途
a.实现字符串对象(StringObject):
数据库的键总是包含一个sds值,而数据库的值保存的是String类型的时候
值中包含sds值,否则包含的是long类型的值b.在redis程序内部用作 char* 类型的替代品:
*char类型的功能单一抽象层次低不能支持redis的一些常用操作(长度计算和追加操作)
4.优化 Append 追加操作
当新 String<1M,会分配 所需大小*2 的空间,String>1M, 多分配 1M 空间。
执行 Append 字符串有额外空间,直到 del操作才会删除这些空间。
或等关闭Redis再次启动,重新载入的String不会有预配空间。
如Append特别多,可修改Redis定时释放预分配空间。
5.Command
set key value
get key
getrange key start end
setrange key offfset value
getbit key offset
setbit key offset value
setnx key value -- 实现分布式锁 (set if not exist)
MSET key1 value1 key2 value2 .. keyN valueN
MSETNX key1 value1 key2 value2 .. keyN valueN
trlen key
psetex key1 EXPIRY_IN_MILLISECONDS value1
incr key
incrby key increment
incrbyfloat key increment
decr key
decrby key decrement
append key value
3.2 l – List 双向链表
1.底层结构
双向链表:内存使用大,需要才会从压缩转换为双向
压缩列表:内存使用小,创建新的list键时,被优先考虑
a.事务模块使用双向链表来按顺序保存输入的命令
b.服务器模块使用双向链表来保存多个客户端
c.订阅/发送模块使用双向链表来保存订阅模式的多个客户端
d.时间模块使用双向链表来保存时间事件(time event)
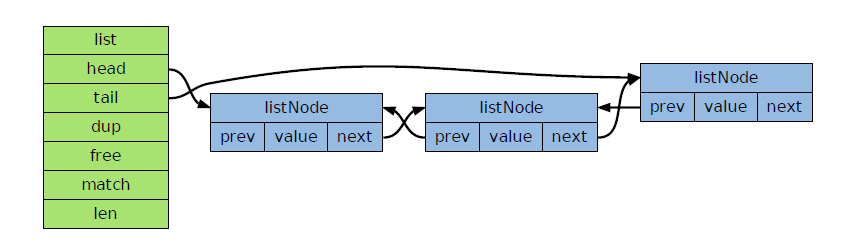
2.双向链表结构
free:删除一个listNode,如此 list->free 函数不为空,先用 free 清空节点值,再执行余下的删除操作,如释放节点

3.链表节点结构

4.特性
双端:head、tail -> 表头/尾插入=O(1),有助于实现push、rpop、rpush、lpop等
无环 带表头指针和表尾指针,带链表长度计数器 length = O(1)
多态(保存各种不同类型的值)
按插入顺序排序的字符串元素的集合
5.list使用
可以实现简单的聊天系统,可以作为不同进程间传递消息的队列
可以每次都按照添加顺序来访问,这很容易扩展到百万级别元素的规模
评级系统中,可以把每个新提交的url添加到一个list,用lrange简单的对结果分页
博客引擎中,可以为每篇 blog 设置一个 list,推入 blog 评论
6.Command
blpop key1 [key2] timeout # 阻塞列表弹出原语
brpop kye1 [key2] timeout # 时间内获取立刻返回值,超时返回null,0表示一直阻塞
brpoplpush source destination timeout
rpoplpush source destination
- 1.安全队列:Message会丢失,不安全
此方法Customer取到消息同时,把消息放入到正在处理的列表中,处理后,使用 LREM 移除正在处理列表中的对应消息。
2.循环列表:如rpoplpush source = destination,客户端在访问一个拥有n个元素的列表时,可以在O(N)时间内一个接一个获取列表元素。
有多个客户端同时对同一个列表进行旋转(rotating):它们会取得不同的元素,直到列表里所有元素都被访问过,又从头开始这个操作。系统:
有 N 个客户端,需要连续不断地对一批元素进行处理,而且处理的过程必须尽可能地快,典型的例子就是服务器上的监控程序:它们需要在尽可能短的时间内,并行地检查一批网站,确保它们的可访问性。这个模式下,客户端时易于扩展的(scalable)且安全的(reliable) 。因为即使客户端把接收到的消息丢失了,消息依然在队列中,等下次跌倒它时候,由其它客户端来处理。
lindex key index
linsert key before|after pivot value
length key
lpop key
rpop key
lrem key count value
lpush key value1 [value2]
lpushx key
rpush key value1 [value2]
rpushx key
lrange key start stop
lrange mylist 0 -2 # 取从开始到倒数第2个元素,-1就是倒数最后1个元素
ltrim key start stop
ltrim mylist 0 3 # 截取下标 [0, 3]的元素
lset key index value
3.3 h – Hash
- 1.filed(String) -> value: 适合存储对象 objects
- 2.每个 hash 可以存储 232 - 1,键值对(40多亿)
1.底层数据结构
1.一般使用 hashtable
2.hash对象使用 ziplist 编码,哈希对象满足如下条件,所有键值对的键和值的字符串长度都 小于64字节 键值对数量小于512个
3.hashtable 通过挂链解决冲突问题
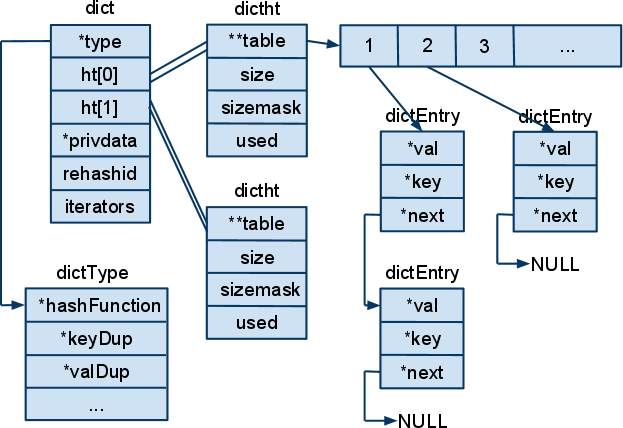
2.Rehash 存储过程源码分析
ziplist 压缩表 包含如下两层,每个key/value存储结果中:
key用一个zipEntry存储
value用一个zipEntry存储
ziplist: zip header、 zip entry、 zip end

zip entry: prevlen、 encoding&length、 value
- prevlen:指前面 zipEntry长度
- encoding&length:指编码字段长度和实际-存储value的长度
- value:真正存的内容

1.以hset命令为例进行分析,整个过程如下:
首先查看 hset 中 key 对应的 value 是否存在,hashTypeLookupWriteOrCreate
判断key和value的长度确定是否需要从 zipList 到 hashtab 转换 hashTypeTryConversion
对key/value进行string层面的编码,解决内存效率问题
更新hash节点中key/value问题其他后续操作的问题
void hsetCommand(redisClient *c) {
int update;
robj *o;
// 取出或新创建哈希对象
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
// 如果需要的话,转换哈希对象的编码
hashTypeTryConversion(o,c->argv,2,3);
// 编码 field 和 value 对象以节约空间
hashTypeTryObjectEncoding(o,&c->argv[2], &c->argv[3]);
// 设置 field 和 value 到 hash
update = hashTypeSet(o,c->argv[2],c->argv[3]);
// 返回状态:显示 field-value 对是新添加还是更新
addReply(c, update ? shared.czero : shared.cone);
// 发送键修改信号
signalModifiedKey(c->db,c->argv[1]);
// 发送事件通知
notifyKeyspaceEvent(REDIS_NOTIFY_HASH,"hset",c->argv[1],c->db->id);
// 将服务器设为脏
server.dirty++
}
2.判断key/value的长度是否超过规定的长度64个字节,由REDIS_HASH_MAX_ZIPLIST_VALUE定义,如果超过64个字节那么久需要将 ziplist 转成 hashtab 对象
/*
* 对 argv 数组中的多个对象进行检查,
* 看是否需要将对象的编码从 REDIS_ENCODING_ZIPLIST 转换成 REDIS_ENCODING_HT
* 注意程序只检查字符串值,因为它们的长度可以在常数时间内取得。
*/
void hashTypeTryConversion(robj *o, robj **argv, int start, int end) {
int i;
// 如果对象不是 ziplist 编码,那么直接返回
if (o->encoding != REDIS_ENCODING_ZIPLIST) return;
// 检查所有输入对象,看它们的字符串值是否超过了指定长度
for (i = start; i <= end; i++) {
// #define REDIS_HASH_MAX_ZIPLIST_VALUE 64
if (sdsEncodedObject(argv[i]) &&
sdslen(argv[i]->ptr) > server.hash_max_ziplist_value)
{
// 将对象的编码转换成 REDIS_ENCODING_HT
hashTypeConvert(o, REDIS_ENCODING_HT);
break;
}
}
}
3.hash底层的更新操作函数hashTypeSet内部会根据是ziplist还是hashtab进行不同的处理逻辑
在ziplist当中会判断ziplist存储数据的长度来判断是否需要转为hashtab数据结构,其中长度判断是通过#define REDIS_HASH_MAX_ZIPLIST_ENTRIES 512定义的。
/*
* 将给定的 field-value 对添加到 hash 中,
* 如果 field 已经存在,那么删除旧的值,并关联新值。
*
* 这个函数负责对 field 和 value 参数进行引用计数自增。
*
* 返回 0 表示元素已经存在,这次函数调用执行的是更新操作。
*
* 返回 1 则表示函数执行的是新添加操作。
*/
int hashTypeSet(robj *o, robj *field, robj *value) {
int update = 0;
// 添加到 ziplist
if (o->encoding == REDIS_ENCODING_ZIPLIST) {
unsigned char *zl, *fptr, *vptr;
// 解码成字符串或者数字
field = getDecodedObject(field);
value = getDecodedObject(value);
// 遍历整个 ziplist ,尝试查找并更新 field (如果它已经存在的话)
zl = o->ptr;
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) {
// 定位到域 field
fptr = ziplistFind(fptr, field->ptr, sdslen(field->ptr), 1);
if (fptr != NULL) {
/* Grab pointer to the value (fptr points to the field) */
// 定位到域的值
vptr = ziplistNext(zl, fptr);
redisAssert(vptr != NULL);
// 标识这次操作为更新操作
update = 1;
/* Delete value */
// 删除旧的键值对
zl = ziplistDelete(zl, &vptr);
/* Insert new value */
// 添加新的键值对
zl = ziplistInsert(zl, vptr, value->ptr, sdslen(value->ptr));
}
}
// 如果这不是更新操作,那么这就是一个添加操作
if (!update) {
/* Push new field/value pair onto the tail of the ziplist */
// 将新的 field-value 对推入到 ziplist 的末尾
zl = ziplistPush(zl, field->ptr, sdslen(field->ptr), ZIPLIST_TAIL);
zl = ziplistPush(zl, value->ptr, sdslen(value->ptr), ZIPLIST_TAIL);
}
// 更新对象指针
o->ptr = zl;
// 释放临时对象
decrRefCount(field);
decrRefCount(value);
// 检查在添加操作完成之后,是否需要将 ZIPLIST 编码转换成 HT 编码
// #define REDIS_HASH_MAX_ZIPLIST_ENTRIES 512
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, REDIS_ENCODING_HT);
// 添加到字典
} else if (o->encoding == REDIS_ENCODING_HT) {
// 添加或替换键值对到字典
// 添加返回 1 ,替换返回 0
if (dictReplace(o->ptr, field, value)) { /* Insert */
incrRefCount(field);
} else { /* Update */
update = 1;
}
incrRefCount(value);
} else {
redisPanic("Unknown hash encoding");
}
// 更新/添加指示变量
return update;
}
3.Command
hset key field value
hmset key field1 value1 [field2 value2]
hget key field
hmget key field1 [field2]
hgetall key
hvals key
案例:
> hmset user:1000 username antirez birthyear 1977 verified 1
OK
> hget user:1000 username
"antirez"
> hget user:1000 birthyear
"1977"
> hgetall user:1000
1) "username"
2) "antirez"
3) "birthyear"
4) "1977"
5) "verified"
6) "1"
hdel key field1 [field2]
hexists key field
hkeys key
hlen key
hincrby key field increment #整数上增
hincrbyfloat key field increment #浮点数上增
案例:
> hincrby user:1000 birthyear 10
(integer) 1987
> hincrby user:1000 birthyear 10
(integer) 1997
hscan key cursor [MATCH pattern] [COUNT count]
3.4 s – Set
1.String 的无序排列,不可重复
2.实现机制:Hash ->DML O(1) 最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)
1.底层数据结构
intset: 整数集合,set保存的所有元素都是 int,set 保存对象数量 <= 512,满足上述条件 使用intset
hashtable: 普通的哈希表(key为set的值,value为null)
2.场景
1.表示对象间关系,可以用来表示标记
2.建模:对每个希望标记的对象使用 set, set包含对象相关的标签ID
#给新闻1000打了4个标签
> sadd [news:1000:tags](news:1000:tags) 1 2 5 77
(integer) 4
#有时候我可能也会需要相反的关系:所有被打上相同标签的新闻列表
> sadd tag:1:news 1000
(integer) 1
> sadd tag:2:news 1000
(integer) 1
> sadd tag:5:news 1000
(integer) 1
> sadd tag:77:news 1000
(integer) 1
#获取一个对象的所有 tag 是很方便的
> smembers [news:1000:tags](news:1000:tags)
1. 5
2. 1
3. 77
4. 2
==================== 如用来发牌
> sadd deck C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 CJ CQ CK
D1 D2 D3 D4 D5 D6 D7 D8 D9 D10 DJ DQ DK H1 H2 H3
H4 H5 H6 H7 H8 H9 H10 HJ HQ HK S1 S2 S3 S4 S5 S6
S7 S8 S9 S10 SJ SQ SK
(integer) 52
> sunionstore game:1:deck deck # 复制牌
(integer) 52
#给1号玩家发5张牌
> spop game:1:deck
"C6"
> spop game:1:deck
"CQ"
> spop game:1:deck
"D1"
> spop game:1:deck
"CJ"
> spop game:1:deck
"SJ"
3.Command
sadd key member1 [member2]
spop key
srandommember key [count]
srem key member1 [member2]
scard key
smembers key
sismember key member
案例:
> sadd myset 1 2 3
(integer) 3
> smembers myset
1. 3
2. 1
3. 2
smove source destination member
sdiff key1 [key2] # 差集
sinter key1 [key2] # 交集
sunion key1 [key2] # 并集
sdiffstore destination key1 [key2]
sinterstore destination key1 [key2]
sunionstore destination key1 [key2]
sscan key cursor [MATCH pattern] [COUNT count]
4.set 存储过程
1.sadd 添加过程
1.检查set是否存在不存在则创建一个set结合
2.根据传入的set集合一个个添加,添加的时候需要进行内存压缩
3.setTypeAdd执行set添加过程中会判断是否进行编码转换
void saddCommand(redisClient *c) {
robj *set;
int j, added = 0;
// 取出集合对象
set = lookupKeyWrite(c->db,c->argv[1]);
// 对象不存在,创建一个新的,并将它关联到数据库
if (set == NULL) {
set = setTypeCreate(c->argv[2]);
dbAdd(c->db,c->argv[1],set);
// 对象存在,检查类型
} else {
if (set->type != REDIS_SET) {
addReply(c,shared.wrongtypeerr);
return;
}
}
// 将所有输入元素添加到集合中
for (j = 2; j < c->argc; j++) {
c->argv[j] = tryObjectEncoding(c->argv[j]);
// 只有元素未存在于集合时,才算一次成功添加
if (setTypeAdd(set,c->argv[j])) added++;
}
// 如果有至少一个元素被成功添加,那么执行以下程序
if (added) {
// 发送键修改信号
signalModifiedKey(c->db,c->argv[1]);
// 发送事件通知
notifyKeyspaceEvent(REDIS_NOTIFY_SET,"sadd",c->argv[1],c->db->id);
}
// 将数据库设为脏
server.dirty += added;
// 返回添加元素的数量
addReplyLongLong(c,added);
}
2.set的单个元素的添加过程
是hashtable的编码,走hashtable的元素添加,
-
是intset则如下判断:
- 1.能够转成int的对象(isObjectRepresentableAsLongLong)就用intset保存
2.如果用intset保存的时候,如果长度超过 512(REDIS_SET_MAX_INTSET_ENTRIES)就转为hashtable编码
- 其他情况统一用hashtable进行存储
/*
* 多态 add 操作
*
* 添加成功返回 1 ,如果元素已经存在,返回 0 。
*/
int setTypeAdd(robj *subject, robj *value) {
long long llval;
// 字典
if (subject->encoding == REDIS_ENCODING_HT) {
// 将 value 作为键, NULL 作为值,将元素添加到字典中
if (dictAdd(subject->ptr,value,NULL) == DICT_OK) {
incrRefCount(value);
return 1;
}
// intset
} else if (subject->encoding == REDIS_ENCODING_INTSET) {
// 如果对象的值可以编码为整数的话,那么将对象的值添加到 intset 中
if (isObjectRepresentableAsLongLong(value,&llval) == REDIS_OK) {
uint8_t success = 0;
subject->ptr = intsetAdd(subject->ptr,llval,&success);
if (success) {
// 添加成功
// 检查集合在添加新元素之后是否需要转换为字典
// #define REDIS_SET_MAX_INTSET_ENTRIES 512
if (intsetLen(subject->ptr) > server.set_max_intset_entries)
setTypeConvert(subject,REDIS_ENCODING_HT);
return 1;
}
// 如果对象的值不能编码为整数,那么将集合从 intset 编码转换为 HT 编码
// 然后再执行添加操作
} else {
setTypeConvert(subject,REDIS_ENCODING_HT);
redisAssertWithInfo(NULL,value,dictAdd(subject->ptr,value,NULL) == DICT_OK);
incrRefCount(value);
return 1;
}
// 未知编码
} else {
redisPanic("Unknown set encoding");
}
// 添加失败,元素已经存在
return 0;
}
3.5 z – Zset Sorted Set
1.不重复 String
2.每个element都关联一个double类型分数,以此为依据进行排序
3.element唯一,score可以重复
4.set 通过 hash 实现,添加、删除、查找 == o(1) 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)
1.数据结构
- 1.ziplist:element使用2个紧挨的 ziplist 节点保存 ,1个保存元素成员,2个保存元素的分值
有序集合保存的元素数量小于128个
有序集合保存的所有元素的长度小于64字节
// 以上条件下 使用ziplist
- 2.skiplist:按顺序保存元素及分值,用 dict 保存元素 - 分值映射关系
2.存储过程
1.解析参数得到每个元素及其对应的分值
2.查找key对应的zset是否存在不存在则创建
3.如果存储格式是ziplist,那么在执行添加的过程中我们需要区分元素存在和不存在两种情况,存在情况下先删除后添加;
不存在情况下则添加并且需要考虑元素的长度是否超出限制或实际已有的元素个数是否超过最大限制进而决定是否转为skiplist对象4.如果存储格式是skiplist,那么在执行添加的过程中我们需要区分元素存在和不存在两种情况,存在的情况下先删除后添加,不存在情况下那么就直接添加,在skiplist当中添加完以后我们同时需要更新dict的对象
void zaddGenericCommand(redisClient *c, int incr) {
static char *nanerr = "resulting score is not a number (NaN)";
robj *key = c->argv[1];
robj *ele;
robj *zobj;
robj *curobj;
double score = 0, *scores = NULL, curscore = 0.0;
int j, elements = (c->argc-2)/2;
int added = 0, updated = 0;
// 输入的 score - member 参数必须是成对出现的
if (c->argc % 2) {
addReply(c,shared.syntaxerr);
return;
}
// 取出所有输入的 score 分值
scores = zmalloc(sizeof(double)*elements);
for (j = 0; j < elements; j++) {
if (getDoubleFromObjectOrReply(c,c->argv[2+j*2],&scores[j],NULL)
!= REDIS_OK) goto cleanup;
}
// 取出有序集合对象
zobj = lookupKeyWrite(c->db,key);
if (zobj == NULL) {
// 有序集合不存在,创建新有序集合
if (server.zset_max_ziplist_entries == 0 ||
server.zset_max_ziplist_value < sdslen(c->argv[3]->ptr))
{
zobj = createZsetObject();
} else {
zobj = createZsetZiplistObject();
}
// 关联对象到数据库
dbAdd(c->db,key,zobj);
} else {
// 对象存在,检查类型
if (zobj->type != REDIS_ZSET) {
addReply(c,shared.wrongtypeerr);
goto cleanup;
}
}
// 处理所有元素
for (j = 0; j < elements; j++) {
score = scores[j];
// 有序集合为 ziplist 编码
if (zobj->encoding == REDIS_ENCODING_ZIPLIST) {
unsigned char *eptr;
// 查找成员
ele = c->argv[3+j*2];
if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {
// 成员已存在
// ZINCRYBY 命令时使用
if (incr) {
score += curscore;
if (isnan(score)) {
addReplyError(c,nanerr);
goto cleanup;
}
}
// 执行 ZINCRYBY 命令时,
// 或者用户通过 ZADD 修改成员的分值时执行
if (score != curscore) {
// 删除已有元素
zobj->ptr = zzlDelete(zobj->ptr,eptr);
// 重新插入元素
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
// 计数器
server.dirty++;
updated++;
}
} else {
// 元素不存在,直接添加
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
// 查看元素的数量,
// 看是否需要将 ZIPLIST 编码转换为有序集合
if (zzlLength(zobj->ptr) > server.zset_max_ziplist_entries)
zsetConvert(zobj,REDIS_ENCODING_SKIPLIST);
// 查看新添加元素的长度
// 看是否需要将 ZIPLIST 编码转换为有序集合
if (sdslen(ele->ptr) > server.zset_max_ziplist_value)
zsetConvert(zobj,REDIS_ENCODING_SKIPLIST);
server.dirty++;
added++;
}
// 有序集合为 SKIPLIST 编码
} else if (zobj->encoding == REDIS_ENCODING_SKIPLIST) {
zset *zs = zobj->ptr;
zskiplistNode *znode;
dictEntry *de;
// 编码对象
ele = c->argv[3+j*2] = tryObjectEncoding(c->argv[3+j*2]);
// 查看成员是否存在
de = dictFind(zs->dict,ele);
if (de != NULL) {
// 成员存在
// 取出成员
curobj = dictGetKey(de);
// 取出分值
curscore = *(double*)dictGetVal(de);
// ZINCRYBY 时执行
if (incr) {
score += curscore;
if (isnan(score)) {
addReplyError(c,nanerr);
goto cleanup;
}
}
// 执行 ZINCRYBY 命令时,
// 或者用户通过 ZADD 修改成员的分值时执行
if (score != curscore) {
// 删除原有元素
redisAssertWithInfo(c,curobj,zslDelete(zs->zsl,curscore,curobj));
// 重新插入元素
znode = zslInsert(zs->zsl,score,curobj);
incrRefCount(curobj); /* Re-inserted in skiplist. */
// 更新字典的分值指针
dictGetVal(de) = &znode->score; /* Update score ptr. */
server.dirty++;
updated++;
}
} else {
// 元素不存在,直接添加到跳跃表
znode = zslInsert(zs->zsl,score,ele);
incrRefCount(ele); /* Inserted in skiplist. */
// 将元素关联到字典
redisAssertWithInfo(c,NULL,dictAdd(zs->dict,ele,&znode->score) == DICT_OK);
incrRefCount(ele); /* Added to dictionary. */
server.dirty++;
added++;
}
} else {
redisPanic("Unknown sorted set encoding");
}
}
if (incr) /* ZINCRBY */
addReplyDouble(c,score);
else /* ZADD */
addReplyLongLong(c,added);
cleanup:
zfree(scores);
if (added || updated) {
signalModifiedKey(c->db,key);
notifyKeyspaceEvent(REDIS_NOTIFY_ZSET,
incr ? "zincr" : "zadd", key, c->db->id);
}
}
3.Command
zadd key source1 member1 [source2 member2]
zrem key member [member...]
zremrangebylex key min max
zremrangebyrank key start stop
zcard key
zrank key member
zinterstore destination numkeys key[key…]
zcount key min max
zlexcount key min max
zrange key start stop [withscores]
zrangebylex key min max [LIMIT offset count]
zrangebyscore key min max [WITHSCORES] [LIMIT]
参考:
文档信息
- 本文作者:jiushun.cheng
- 本文链接:https://minipa.github.io/2016/07/20/redis-base-data/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)