
1 dict 字典 双Hahs
1.字典 映射 关联数组(associative array)
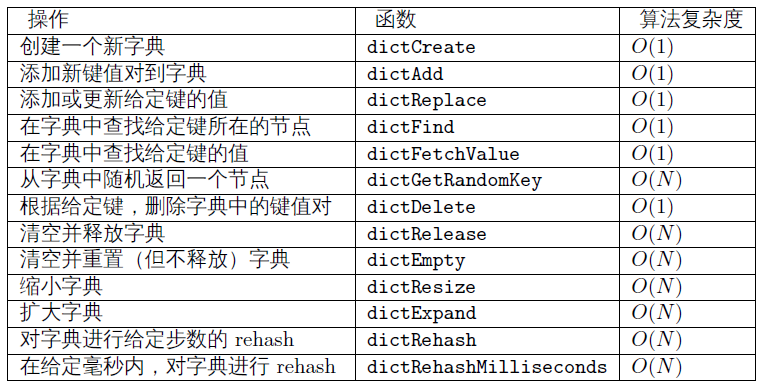
dictht[0] 字典主要使用的哈希表
dictht[1] rehash 时使用
/*
* 字典
**
每个字典使用两个哈希表,用于实现渐进式rehash
*/
typedef struct dict {
// 特定于类型的处理函数
dictType *type;
// 类型处理函数的私有数据
void *privdata;
// 哈希表(2 个)
dictht ht[2];
// 记录rehash 进度的标志,值为-1 表示rehash 未进行
int rehashidx;
// 当前正在运作的安全迭代器数量
int iterators;
} dict;
2.table:
数组每个元素都是一个指向dictEntry结构的指针
每个 dictEntry 都保存一个 k_v,和指向另一个 dictEntry 的结构指针
/*
* 哈希表
*/
typedef struct dictht {
// 哈希表节点指针数组(俗称桶,bucket)
dictEntry **table;
// 指针数组的大小
unsigned long size;
// 指针数组的长度掩码,用于计算索引值
unsigned long sizemask;
// 哈希表现有的节点数量
unsigned long used;
} dictht;
/*
* 哈希表节点
*/
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 链往后继节点
struct dictEntry *next;
} dictEntry;
3.Hash
1.用途
- 1)实现数据库键空间(key space) redis是一个键值对数据库,数据库中的键值对就是由字典保存:
每个数据库都有一个与之相对应的字典,这个字典被称为键空间(key space)
当用户添加一个键值对到数据库时(不论数据库是什么类型),程序就将该键值对添加到键空间;
当用户从数据库删除一个键值对时,程序就会将这个键值对从键空间删除
2)用作Hash类型键的其中一种底层实现
• 字典是由键值对构成的抽象数据结构
• Redis 中的数据库和哈希键都是基于字典来实现的
• Redis 字典的底层实现为哈希表,每个字典使用两个哈希表,一般情况下只使用0号哈希表,只有在rehash进行时,才会使用0号和1号哈希表
• 哈希表使用链地址法来解决键冲突的问题
• rehash可以用于扩展和收缩哈希表
• 对哈希表的rehash是分多次、渐进式地进行
4.Rehash
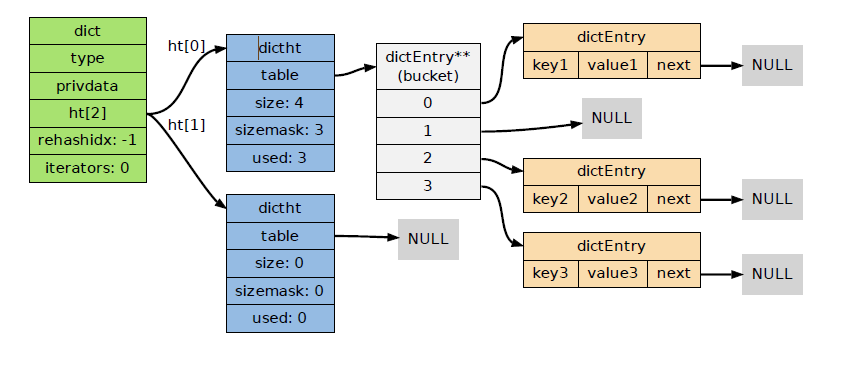
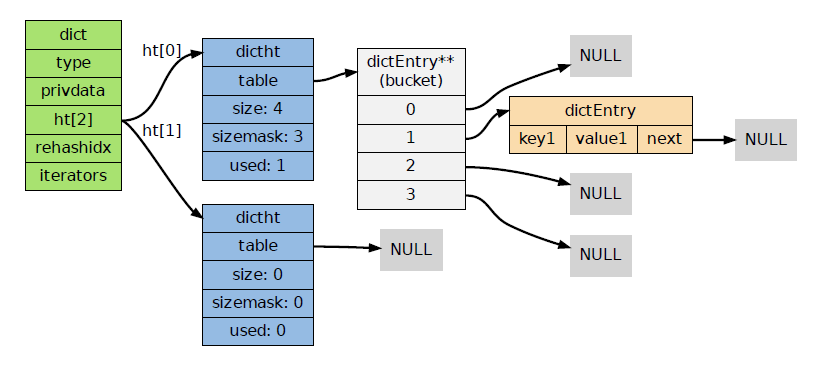
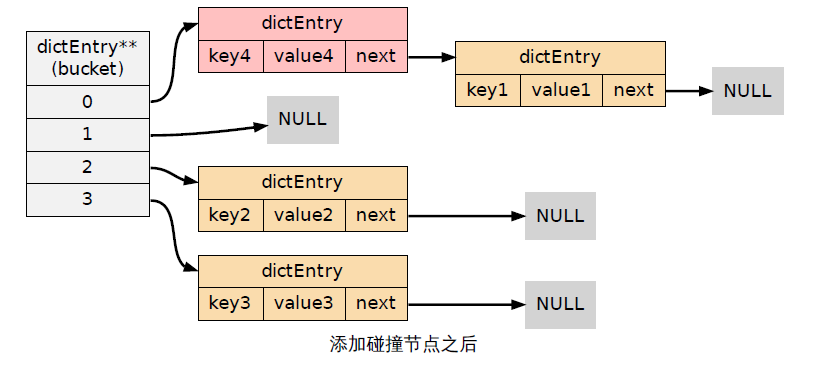
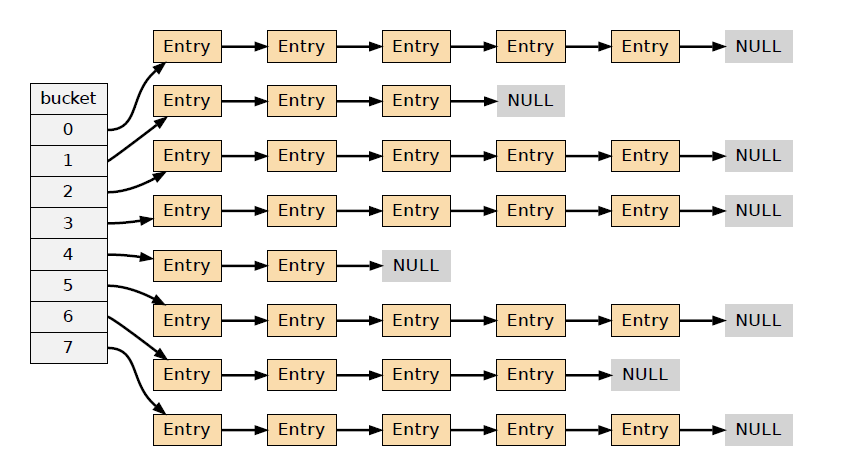
- 渐进式Rehash
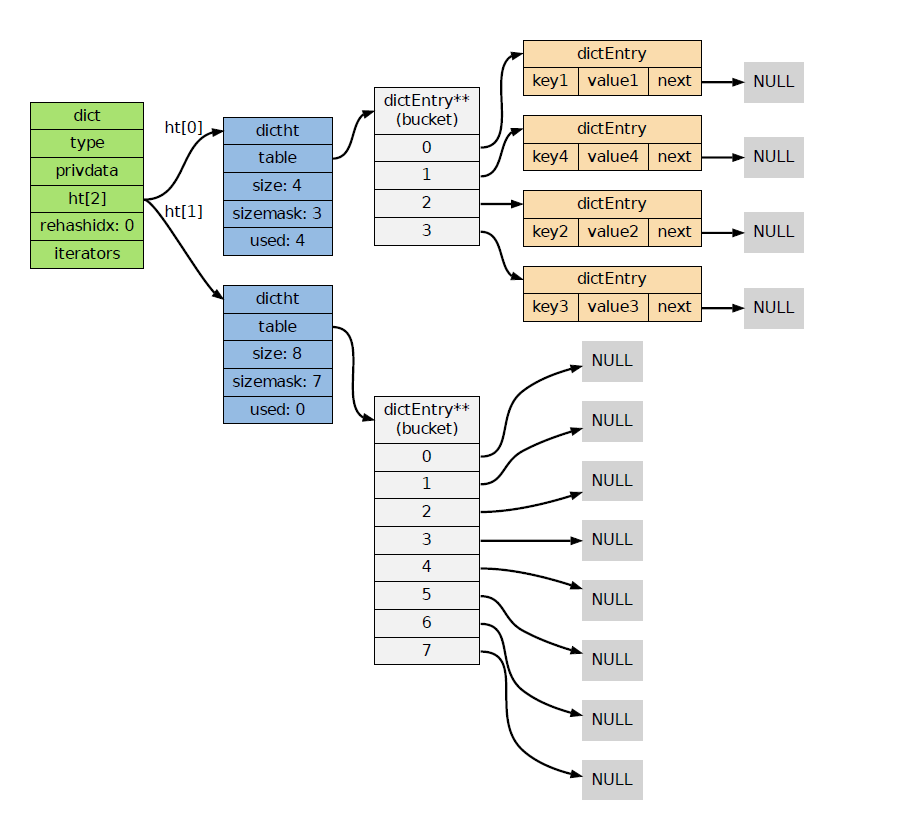
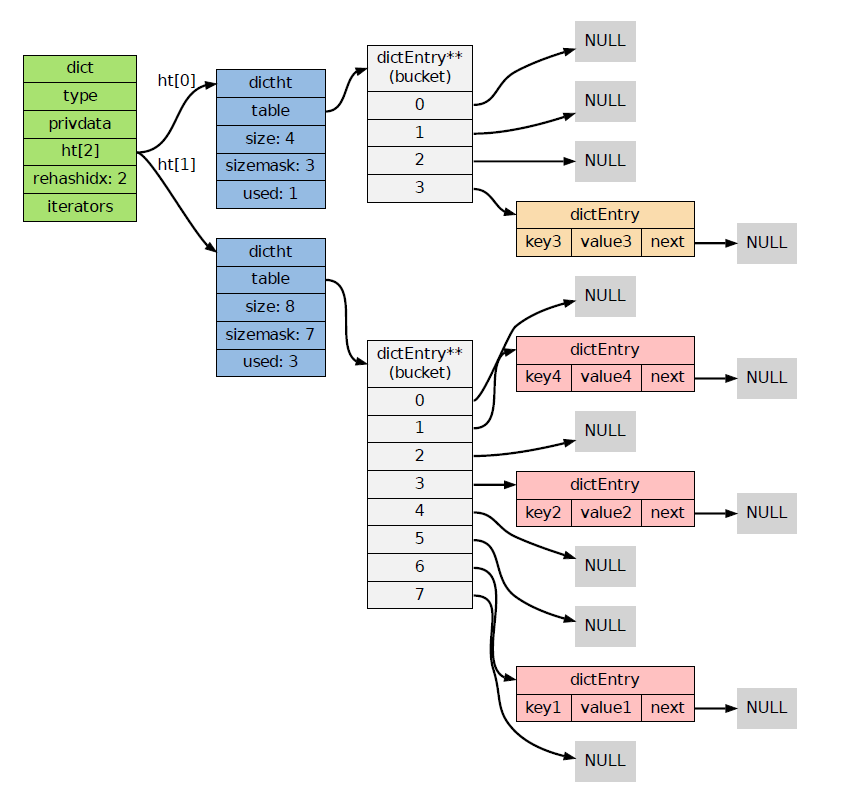
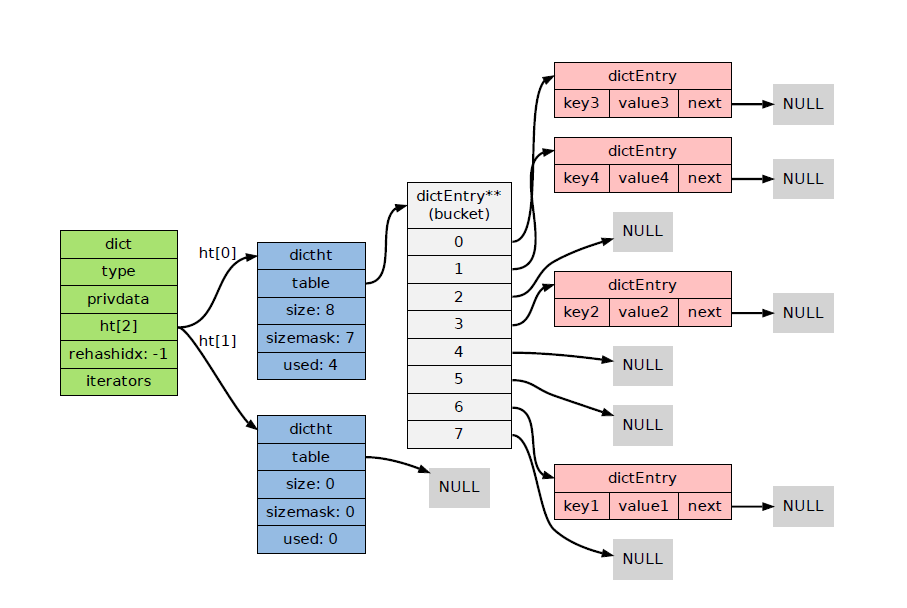
2 intset 整数集合
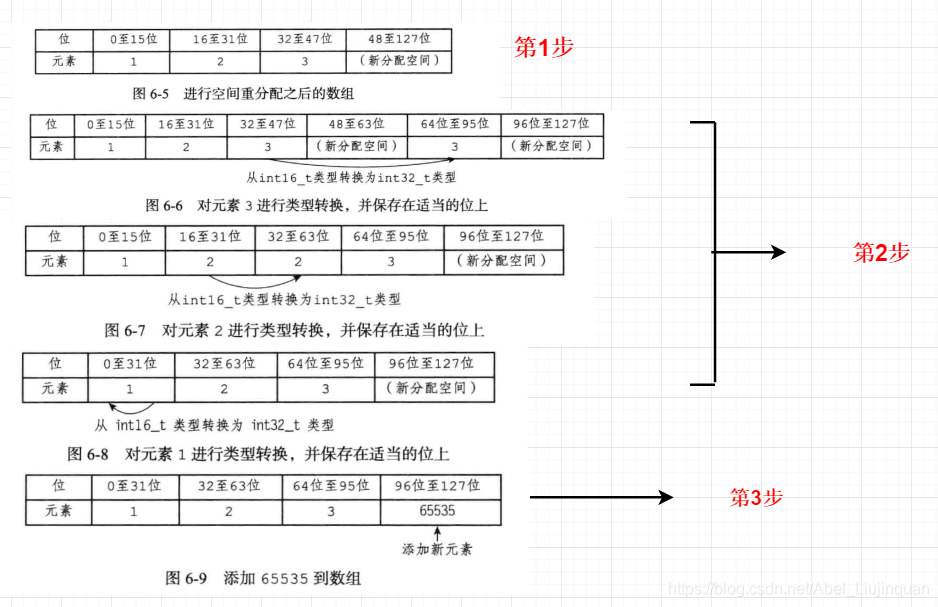
保存整数值的集合抽象数据结构,可以保存类型为 int16_t 、int32_t 或者 int64_t 的整数值,并且保证集合中不出现重复值。

整数集合的升级
添加一个新元素到整数集合里面,但是新元素的类型比整数集合原有的元素类型都要长时,我们就要对整数集合进行升级
升级整数集合并添加新元素共分为三步进行:
1)根据新元素的类型,扩展整数集合底层数组的空间大小,并为新元素分配空间
2)将底层数组现有的所有元素都转换成与新元素相同的类型,并将类型转换后的元素继续维持底层数组的有序性质不变
3)将新元素添加到底层数组里面
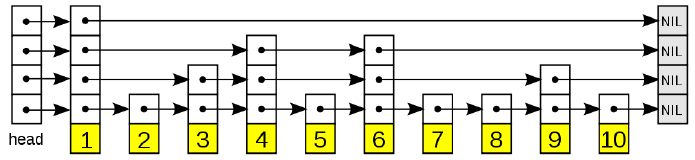
3.skiplist 跳跃表 –分值有序
一种随机化数据,以有序方式 在层次化链表中 保存数据
1.应用
在redis的唯一作用就是实现有序集数据类型,将指向有序集的score值和member域的指针作为元素,并以score值为索引,对有序集元素进行排序。
2.实现
- a.score值可重复
b.对比一个元素需要同时检查它的score值和member域
- c. 每个节点带有高度为1层的后退指针,用于从表尾方向向表头方向迭代
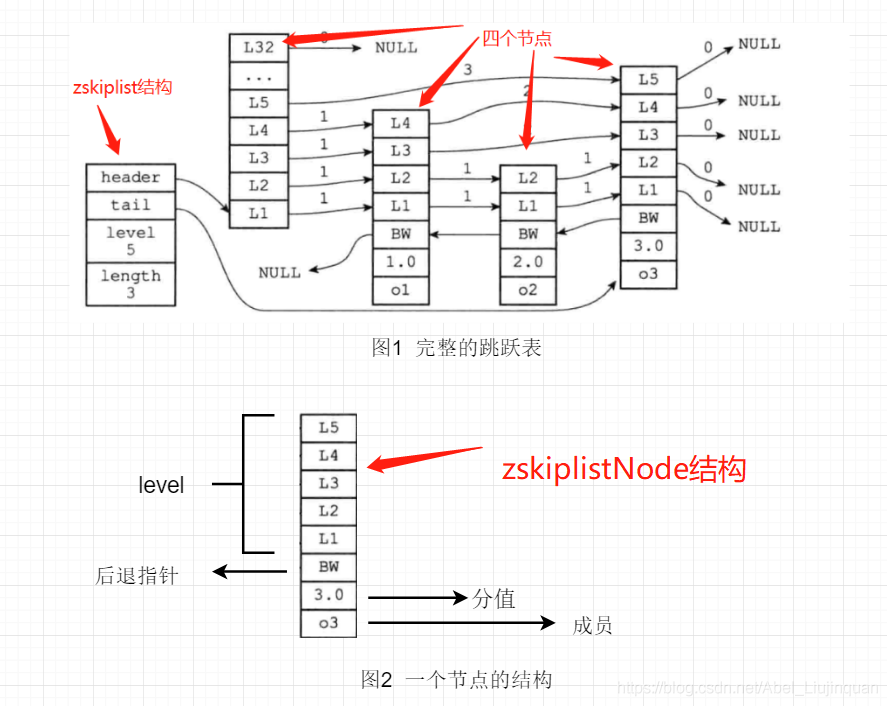
3.结构
typedef struct zskiplist {
// 头节点,尾节点
struct zskiplistNode *header, *tail;
// 节点数量
unsigned long length;
// 目前表内节点的最大层数
int level;
} zskiplist;
跳跃表的节点由redis.h/zskiplistNode 定义:
typedef struct zskiplistNode {
// member 对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 这个层跨越的节点数量
unsigned int span;
} level[];
} zskiplistNode;
• 表头(head):负责维护跳跃表的节点指针。
• 跳跃表节点:保存着元素值,以及多个层。
• 层:保存着指向其他元素的指针
高层的指针越过的元素数量大于等于低层的指针,为了提高查找的效率,程序总是从高层先开始访问,然后随着元素值范围的缩小,慢慢降低层次
• 表尾:全部由NULL 组成,表示跳跃表的末尾
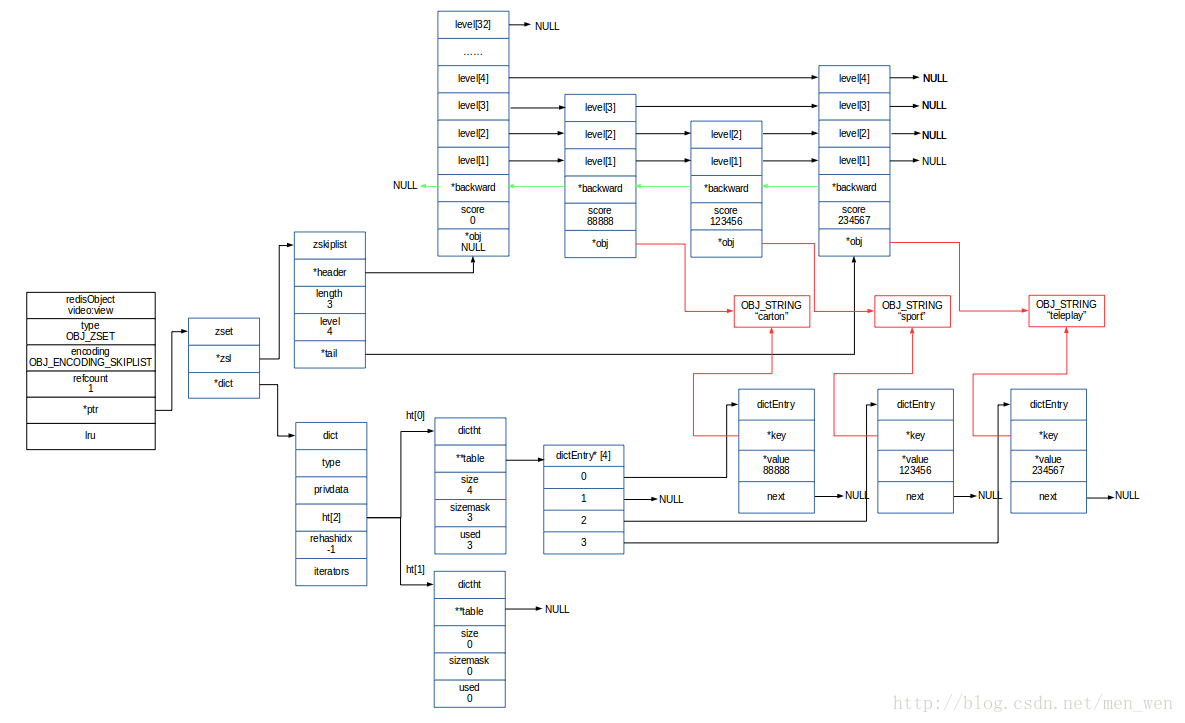
4.skiplist – dict
1.dict 保存 key/value, key 为 element 元素,value为 score 分值
2.skiplist 保存有序的元素列表,每节点保存元素和分值
// 两种结构下元素指向相同的位置
4.ziplist 压缩表
是列表键和哈希键的底层实现之一 一个列表键值包含少量列表键,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来做列表键的底层实现
1.压缩列表构成
由一系列特殊编码的连续内存块组成的顺序型数据结构,一个压缩列表可以包含任意多个节点 (entry) ,每个节点可以保存一个字节数组或者一个整数值


zlbytes属性:表示压缩列表的总字节长度
zltail属性:记录压缩列表表尾节点距离压缩列表的起始地址有多少字节
zllen属性:记录了压缩列表包含的节点数量
entryX属性:压缩列表包含的各个节点
zlend属性:用于标记压缩列表的末端
2.压缩列表节点结构

previous_entry_length:以字节为单位,记录压缩列表中前一个节点的长度。
程序可以通过指针运算,根据当前节点的起始地址来计算出前一个节点的起始地址,以此实现遍历操作。
encoding属性:记录了节点的content属性所保存数据的类型和长度;
content属性:保存节点的值,可以是一个字节数组或者整数,值的类型和长度由节点的encoding属性决定
3.连锁更新
假设压缩列表中所有节点的previous_entry_length属性都是用1字节来保存,
那么节点的长度只要小于等于253字节previous_entry_length都可以记录,
但是,如果添加一个长度大于253字节的节点,那么下一个节点的previous_entry_length就无法保存该长度的值,
同样的,下下个节点也无法保存上个节点的长度,由此将导致连续多次空间扩展操作
添加节点和删除节点都可能导致连锁更新,但是这种操作出现的几率很低。
参考:
文档信息
- 本文作者:jiushun.cheng
- 本文链接:https://minipa.github.io/2016/07/21/redis-deep-data/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)