
1.Redis 集群
介绍
- 1.提供多个redis-nodes共享数据的程序集
2.cluster不提供 多keys 命令,因为涉及网络移动数据,达不到单点redis多keys那样的性能,高负载会出不可预料错误
- 3.partition 提供一定程度可用性,实际环境下,当某节点宕机或不可达下,继续处理 command
优势
1.自动分隔数据到不同 nodes
2.高课用,部分 nodes 宕机或不可达,能继续处理命令
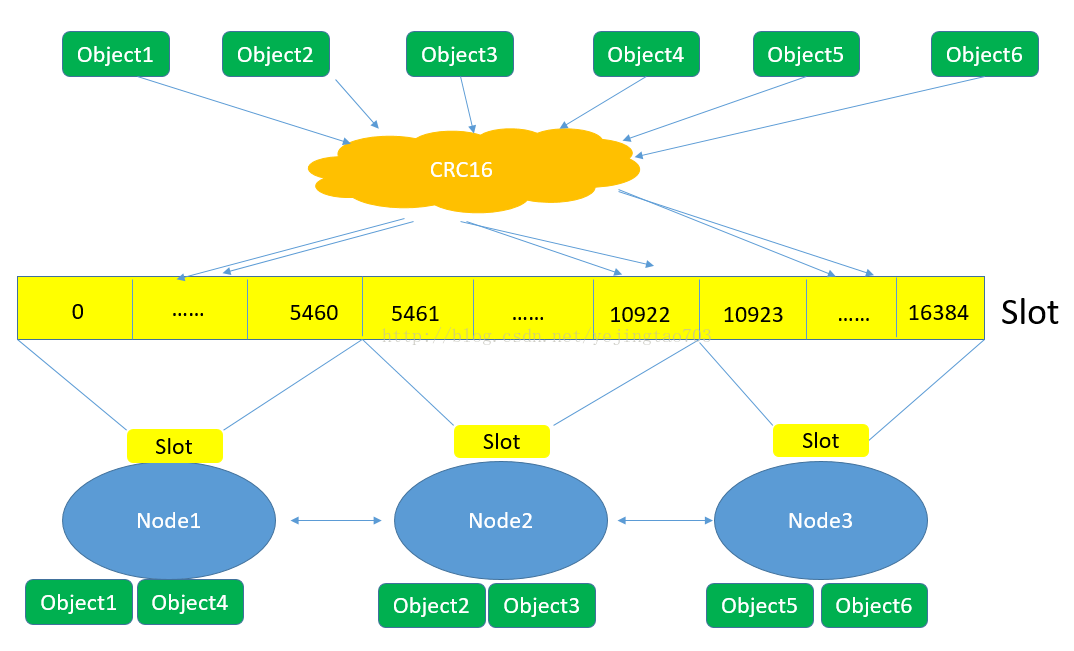
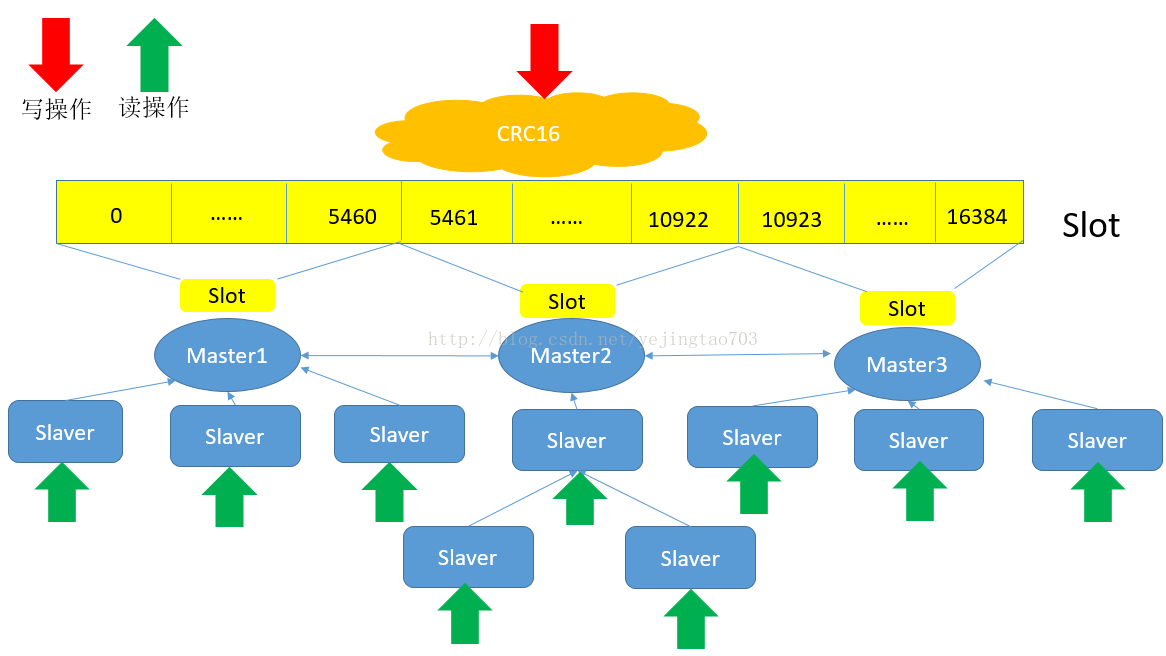
partition 分片
没有用一致性hash,使用 hash槽 Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来,决定放置哪个槽.集群的每个节点负责一部分hash槽
添加node:从其它node负责的hash槽分一部分给新node
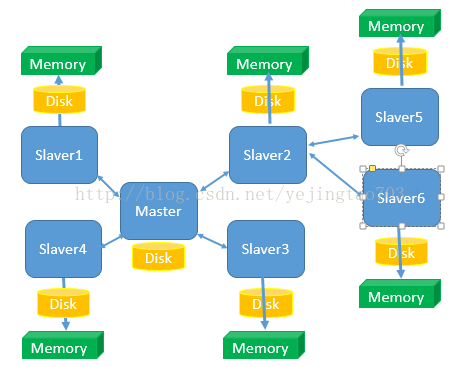
1.可用性 M-S 复制模型
目的:在部分节点失败或大部分节点无法通信下,集群可用
每个node有n-1个复制品
案例:A、B、C集群,C宕机,则C复制的 hash槽 部分不可用
方案:创建A1、B1、C1为slave,B宕机,B1选举为 master 继续服务
2.一致性
Redis不能保证数据强一致,实际clusters中,特定条件下可能丢失write操作
1.cluster用了 异步复制 ,master异步将write操作同步给slave
1)client 请求 master,write1
2)master 回复 client
3)master 将write1 同步给 slave其中同步发生在回复client之后,否则极大影响吞吐量
==> 一致性和性能间平衡
2.另一种情况是,出现网络分区,且一个客户端与至少包括一个主节点在内的少数几个实例被孤立
A 、 B 、 C 、 A1 、 B1 、 C1
客户端 Z1 假设集群中发生网络分区,B + Z1 被故离到小部分了
Z1仍然可以向B写入,但分区时间长到B1被推举到master
则这段时间 Z1->B的write丢失==> redis做了配置 node timeout:
网络分裂期间,Z1向B写命令的最大时间是有限制的,叫 node 超时时间
3.M-S
redis主从命令
SLAVEOF host port: 建立主从关系
1.在Redis运行时动态地修改复制(replication)功能的行为
2.将当前服务器变为指定服务器的slave server
3.如原先就是slave,则会丢失原有数据,成为新 slave
SLAVEOF no one: 关闭slave复制功能
1.原来同步所得的数据集不会被丢弃
2.利用此功能,在master失败时,将slave转为master
Master 端

2.M-S 原理
3.Redis集群目标
1000个节点,表现仍然很好,且可扩展 scalability 是线性的
没有合并操作
写入安全 write safety, 小部分写入会丢失
可用性availability: 觉得大多数主节点可达(master node)
每个不可达master,有从节点slave node可达情况下,分区可用
4.Readonly Node
Redis 复制 (Replication)
分布式数据库为了获取更大的存储容量和更高的并发访问量,
会将原来集中式数据库中的数据分散存储到多个通过网络连接的数据存储节点上
Redis为了解决单点数据库问题,会把数据复制多个副本部署到其他节点上,通过复制,实现Redis的高可用性,实现对数据的冗余备份,保证数据和服务的高度可靠性
从节点的INFO replication信息时,可以知道slave_read_only:1,从节点默认只能读不能写
127.0.0.1:9999> SET key value
(error) READONLY You can't write against a read only slave.
Redis 的复制拓扑结构支持单层或多层复制关系
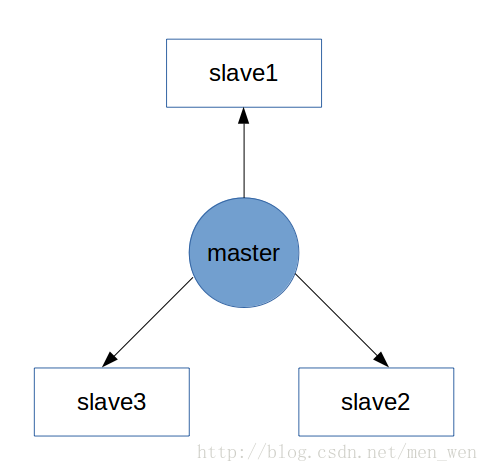
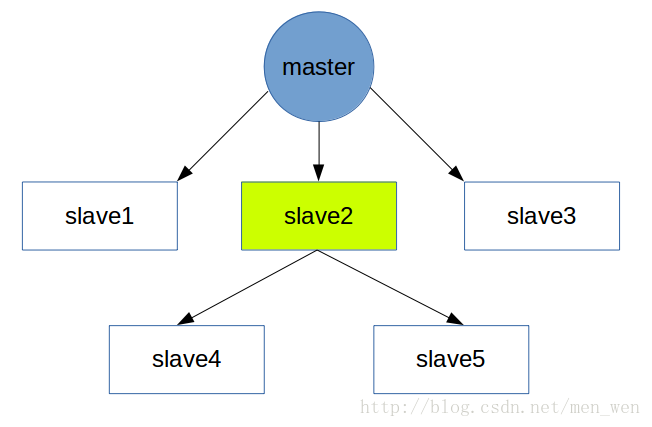
参考:
文档信息
- 本文作者:jiushun.cheng
- 本文链接:https://minipa.github.io/2016/07/26/redis-ms/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)