
1.Read Write 读写分离
- 技术问题主要落在如何实现读库和写库的同步 TODO
2.分库分表
1.mysql 性能瓶颈
- [IO]
- 磁盘IO:热数据太多,数据库缓存放不下,查询产生大量IO ==> 分库 垂直分表
- 网络IO:请求数据太多,带宽不够 ==> 分库
- [CPU]
- SQL:包含 join,group by,order by
非索引字段条件查询等,增加CPU运算的操作
-> SQL优化,建立合适的索引,在业务Service层进行业务计算 - table数据量太大:查询扫描太多,SQL 效率低,CPU 率先出现瓶颈 ==> 水平分表
- SQL:包含 join,group by,order by
3.拆分后事务如何保证
1)两阶段、三阶段提交
2)最终一致性
通常的做法就是补偿
一个业务是 A 调用 B,两个执行成功才算最终成功,当 A 成功之后,B 执行失败如何来通知 A 呢
比较常见的做法是 失败时 B 通过 MQ 将消息告诉 A,A 再来进行回滚。
这种的前提是 A 的回滚操作得是幂等的,不然 B 重复发消息就会出现问题。
4..水平拆分:
按照取模分表拆分之后我们的 查询、修改、删除 也都是取模
==> 如新增一条数据的时候往往需要一张临时表来生成 ID, 然后根据生成的 ID 取模计算出需要写入的是哪张表 (也可以使用分布式 ID 生成器来生成 ID)
==> 不建议做join,建议做两次查询
1.水平分库
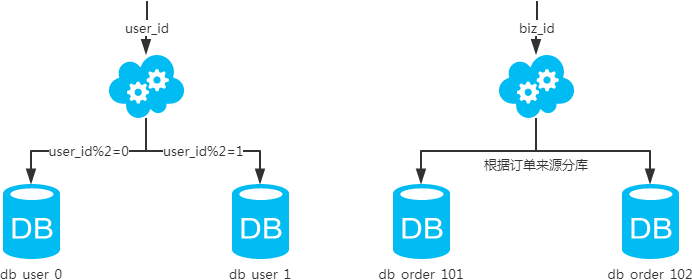
概念:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中
结果:每个库的结构都一样;每个库的数据都不一样,没有交集;所有库的并集是全量数据;
场景:系统绝对并发量上来了,分表难以根本上解决问题,并且还没有明显的业务归属来垂直分库
分析:库多了,io 和 cpu 的压力自然可以成倍缓解
2.水平分表
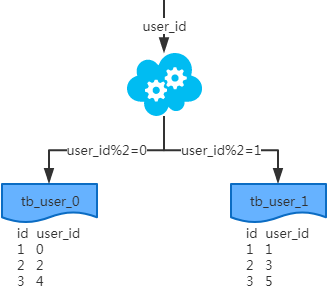
概念:以字段为依据,按照一定策略(hash、range、每月等),将一个表中的数据拆分到多个表中。
结果:每个表的结构都一样;每个表的数据都不一样,没有交集;所有表的并集是全量数据;
场景:系统绝对并发量并没有上来,只是单表的数据量太多,影响了SQL效率,加重了CPU负担,以至于成为瓶颈。
分析:表的数据量少了,单次SQL执行效率高,自然减轻了CPU的负担。
5.垂直拆分
1.垂直分库
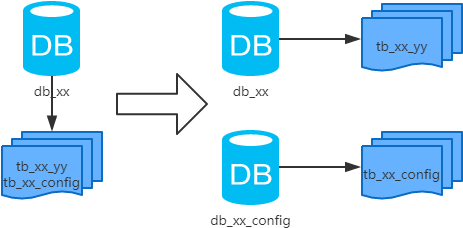
概念:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中, bxg果项目准备的垂直分库
结果:每个库的结构都不一样;每个库的数据也不一样,没有交集;所有库的并集是全量数据;
场景:系统绝对并发量上来了,并且可以抽象出单独的业务模块
分析:到这一步,基本上就可以服务化了
例如,随着业务的发展一些公用的配置表、字典表等越来越多,这时可以将这些表拆到单独的库中,甚至可以服务化。
再有,随着业务的发展孵化出了一套业务模式,这时可以将相关的表拆到单独的库中,甚至可以服务化。
2.垂直分表
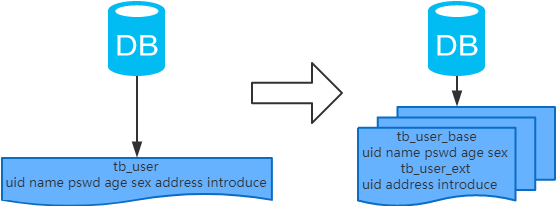
概念:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中
结果:每个表的结构都不一样;每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,
一般是主键,用于关联数据;所有表的并集是全量数据;
场景:系统绝对并发量并没有上来,表的记录并不多,但是字段多,并且热点数据和非热点数据在一起,单行数据所需的存储空间较大。
以至于数据库缓存的数据行减少,查询时会去读磁盘数据产生大量的随机读IO,产生IO瓶颈。
分析:可以用列表页和详情页来帮助理解
垂直分表的拆分原则是将热点数据(可能会冗余经常一起查询的数据)放在一起作为主表,非热点数据放在一起作为扩展表。
这样更多的热点数据就能被缓存下来,进而减少了随机读IO。
拆了之后,要想获得全部数据就需要关联两个表来取数据。
但记住,千万别用join,因为join不仅会增加CPU负担并且会讲两个表耦合在一起(必须在一个数据库实例上) 关联数据,应该在业务Service层做文章,分别获取主表和扩展表数据然后用关联字段关联得到全部数据。
6.拆分工具
1.sharding-sphere、Mycat
sharding-sphere:jar,前身是sharding-jdbc
TDDL:jar,Taobao Distribute Data Layer
Mycat:中间件
2.步骤
根据容量(当前容量和增长量)评估分库或分表个数
-> 选key(均匀)
-> 分表规则(hash或range等)
-> 执行(一般双写)
-> 扩容问题(尽量减少数据的移动)
3.问题
1.非partition key的查询问题
- 详细实用说明,后续再添加做项目具体经验进来,要注意的是拆分时候数据量的大小,数据的转移和可靠性如何保证。
参考:
文档信息
- 本文作者:jiushun.cheng
- 本文链接:https://minipa.github.io/2017/07/22/mysql-distribute/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)