
1.MQ 基础介绍
MessageQueue
消息队列/消息总线
跨进程、异步的通信机制,用于上下游传递消息
消息系统来确保消息的可靠传递
1.实现应用程序
异步、解耦 **
**消息缓冲:流量削锋、错峰流控
消息分发:数据分发、日志收集等等 …2.主流竞品:RabbitMQ ActiveMQ Kafka ZeroMQ RocketMQ;redis也支持 MQ 功能
3.衡量标准:服务性能、数据存储、集群架构
AMQP
Advanced Message Queue Protocol (高级消息队列协议)
是应用层协议的一个开放标准,为面向消息的中间件设计
特征: 面向消息、队列、路由(包括点对点和发布/订阅)可靠性、安全
JDK队列:
JDK已经有很多队列了,都是简单内存队列
使用方法
标准用法: PC 生产者消费者
其他用法: 分布式事物支持, RPC调用
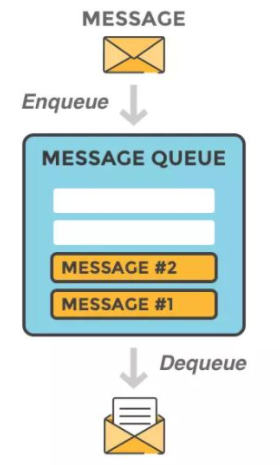
1.P 生产者:把数据放到消息队列
2.C 消费者:从消息队列中取数据
2.设计一个 MQ 的问题
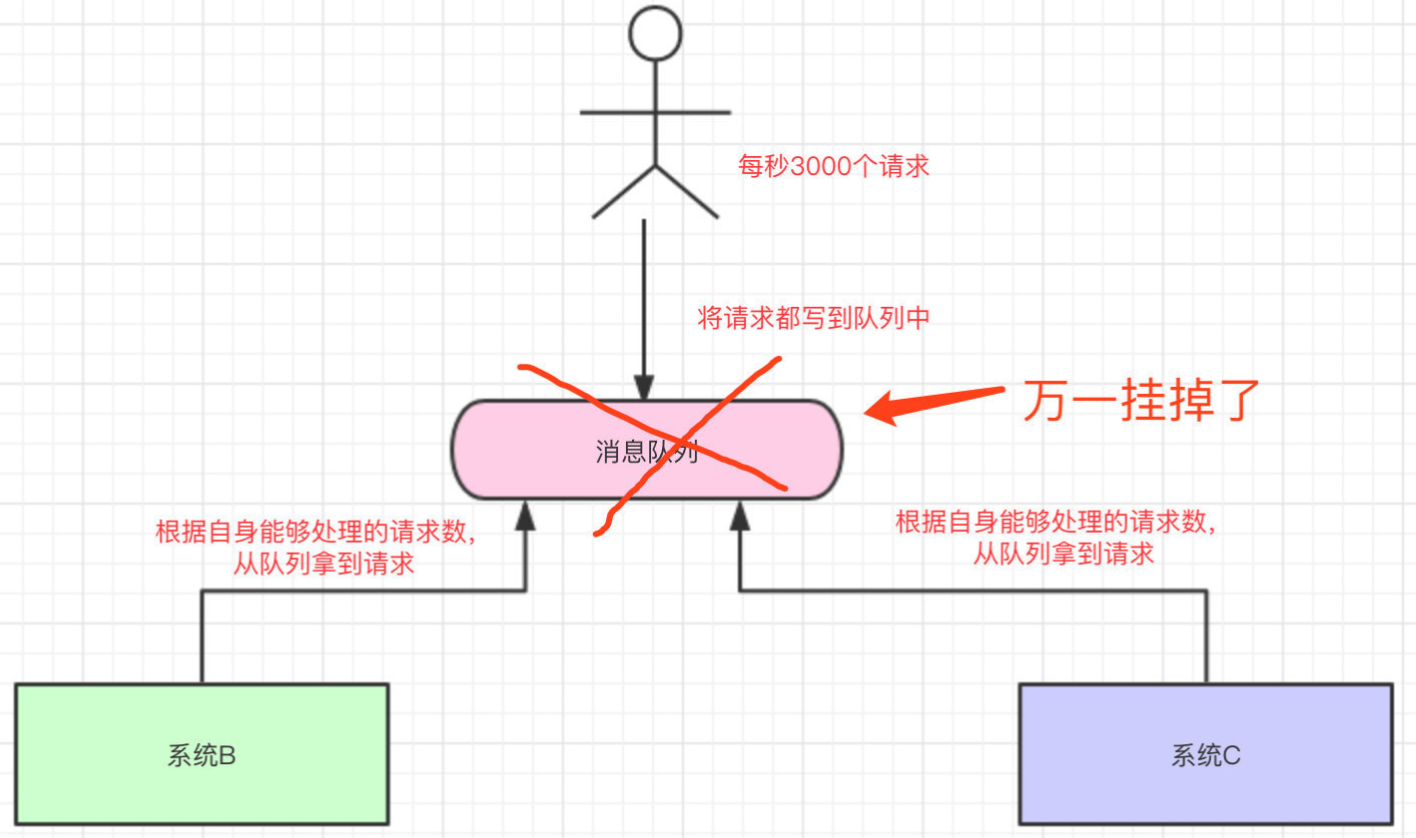
1.高可用
用消息队列来做解耦、异步还是削峰,消息队列肯定不能是单机的,单机的消息队列,万一这台机器挂了,那我们整个系统几乎就是不可用了。
==> 消息队列,都是得集群/分布式
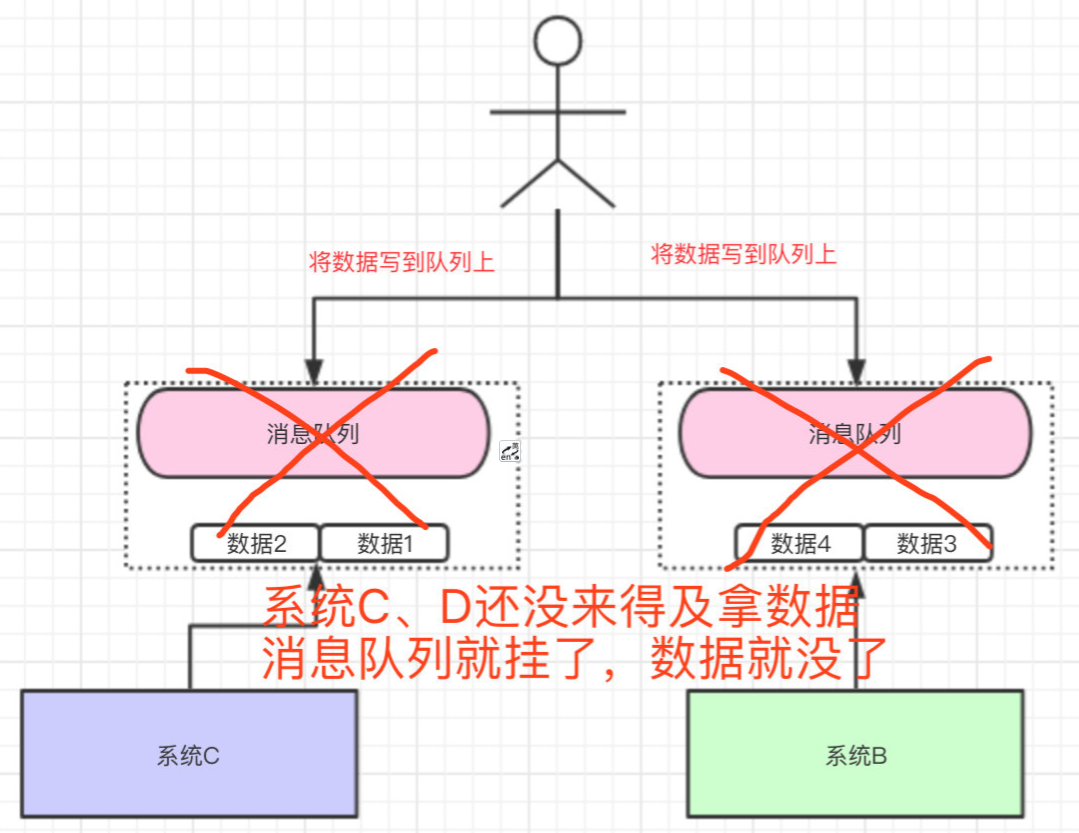
2.数据丢失问题
数据写到消息队列上,系统B和C还没来得及取消息队列的数据,就挂掉了
如果没有做任何的措施,我们的数据就丢了
==>数据要存储:
存在哪里:磁盘?数据库?Redis?分布式文件系统?
方式:同步存储、异步存储
3.消费者怎么得到消息队列的数据
生产者将数据放到消息队列中,消息队列有数据了
push ==> MQ主动通知消费者去拿(俗称push)
pull ==> 消费者不断去轮训查看MQ,看看有没有新的数据,如果有就消费(俗称pull)
4.设计一个消息队列要考虑的问题问题:
- 基础:重复、丢失、顺序、批量,RPC、高可用、可靠投递、消费关系解析等
- 高级主题:批量/异步提高性能、pull模型的系统设计理念、存储子系统的设计、流量控制的设计、公平调度的实现
5.MQ适用场景
业务解耦、最终一致性、削峰/错流、广播等场景 异步RPC的主要手段 强一致性最好是用 RPC
- 2021年1月5日 谁能告诉我强一致性为啥最好?让我自己思考。
6.broker
MQ的一个实例,或者叫一个节点
- 1.是消息队列核心,相当于一个控制中心,负责路由消息、保存订阅和连接、消息确认和控制事务
- 2.broker接口:定义了一些获取broker本身相关信息
添加connection、destination、session、消息生产者、控制事务的接口
3.1 解耦 – 消费者模式
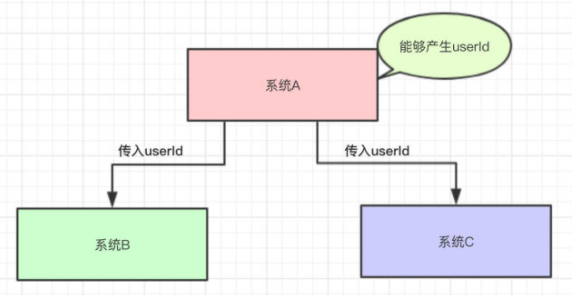
1.系统A可以产生一个userId,系统B和系统C都需要这个userId去做相关的操作
// 伪代码
public class SystemA {
// 系统B和系统C的依赖
SystemB systemB = new SystemB();
SystemC systemC = new SystemC();
// 系统A独有的数据userId
private String userId = "Java3y";
public void doSomething() {
// 系统B和系统C都需要拿着系统A的userId去操作其他的事
systemB.SystemBNeed2do(userId);
systemC.SystemCNeed2do(userId);
}
}
2.系统B的负责人告诉系统A的负责人,现在系统B的SystemBNeed2do(String userId)这个接口不再使用了,让系统A别去调它了,于是就把调用系统B接口的代码给删掉了
public void doSomething() {
// 系统A不再调用系统B的接口了
//systemB.SystemBNeed2do(userId);
systemC.SystemCNeed2do(userId);
}
3.系统D的负责人接了个需求,也需要用到系统A的userId,于是就跑去跟系统A的负责人说:”老哥,我要用到你的userId,你调一下我的接口吧”,于是系统A说:”没问题的,这就搞”
public class SystemA {
// 已经不再需要系统B的依赖了
// SystemB systemB = new SystemB();
// 系统C和系统D的依赖
SystemC systemC = new SystemC();
SystemD systemD = new SystemD();
// 系统A独有的数据
private String userId = "Java3y";
public void doSomething() {
// 已经不再需要系统B的依赖了
//systemB.SystemBNeed2do(userId);
// 系统C和系统D都需要拿着系统A的userId去操作其他的事
systemC.SystemCNeed2do(userId);
systemD.SystemDNeed2do(userId);
}
}
时间飞逝:
又过了几天,系统E的负责人过来了,告诉系统A,需要userId。又过了几天,系统B的负责人过来了,告诉系统A,还是重新掉那个接口吧。
又过了几天,系统F的负责人过来了,告诉系统A,需要userId。……于是系统A的负责人,每天都被这给骚扰着,改来改去,改来改去…….
还有另外一个问题,调用系统C的时候,如果系统C挂了,系统A还得想办法处理。如果调用系统D时,由于网络延迟,请求超时了,那系统A是反馈fail还是重试??
最后,系统A的负责人,觉得隔一段时间就改来改去,没意思,于是就跑路了。
然后,公司招来一个大佬,大佬经过几天熟悉,上来就说:将系统A的userId写到消息队列中,这样系统A就不用经常改动了。为什么呢?下面我们来一起看看:
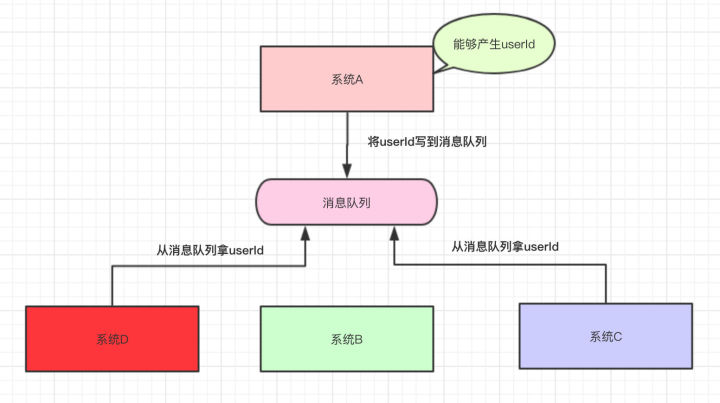
系统A将userId写到消息队列中,系统C和系统D从消息队列中拿数据。
这样有什么好处?系统A只负责把数据写到队列中,谁想要或不想要这个数据(消息),系统A一点都不关心。
即便现在系统D不想要userId这个数据了,系统B又突然想要userId这个数据了,都跟系统A无关,系统A一点代码都不用改。
系统D拿userId不再经过系统A,而是从消息队列里边拿。系统D即便挂了或者请求超时,都跟系统A无关,只跟消息队列有关。
这样一来,系统A与系统B、C、D都解耦了。
==> 消费者模式
解耦了 DBC 三系统
解耦了消息创建 和 消费过程
3.2 异步 – RT响应时间
系统 A 还是直接调用系统 B、C、D
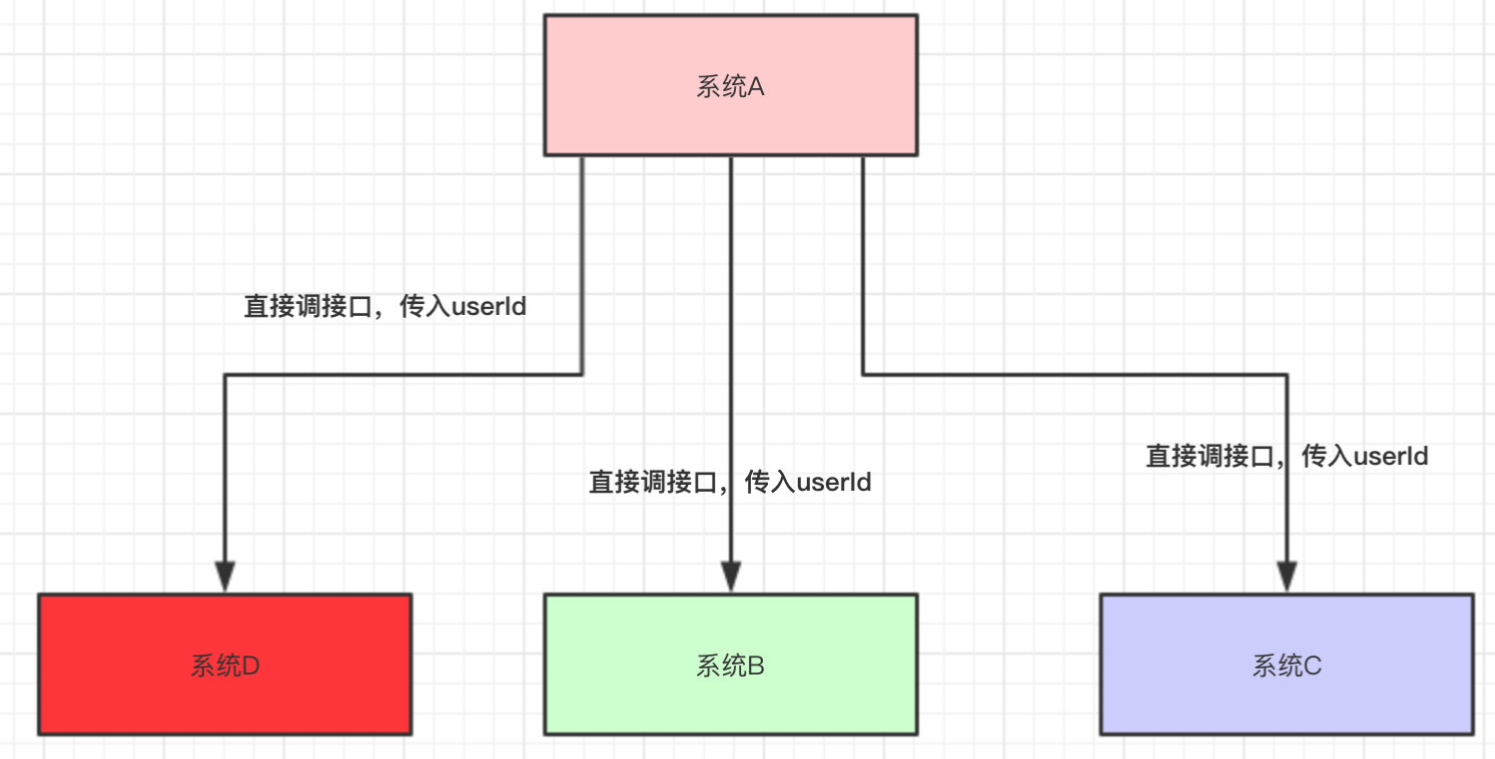
public class SystemA {
SystemB systemB = new SystemB();
SystemC systemC = new SystemC();
SystemD systemD = new SystemD();
// 系统A独有的数据
private String userId ;
public void doOrder() {
// 下订单
userId = this.order();
// 如果下单成功,则安排其他系统做一些事
systemB.SystemBNeed2do(userId);
systemC.SystemCNeed2do(userId);
systemD.SystemDNeed2do(userId);
}
}
假设系统A运算出userId具体的值需要50ms,
调用系统B的接口需要300ms,
调用系统C的接口需要300ms,
调用系统D的接口需要300ms。
那么这次请求就需要50+300+300+300=950ms
并且我们得知,系统A做的是主要的业务,而系统B、C、D是非主要的业务。
比如系统A处理的是订单下单,而系统B是订单下单成功了,那发送一条短信告诉具体的用户此订单已成功,而系统C和系统D也是处理一些小事而已。
那么此时,为了提高用户体验和吞吐量,其实可以异步地调用系统B、C、D的接口。所以,我们可以弄成是这样的:
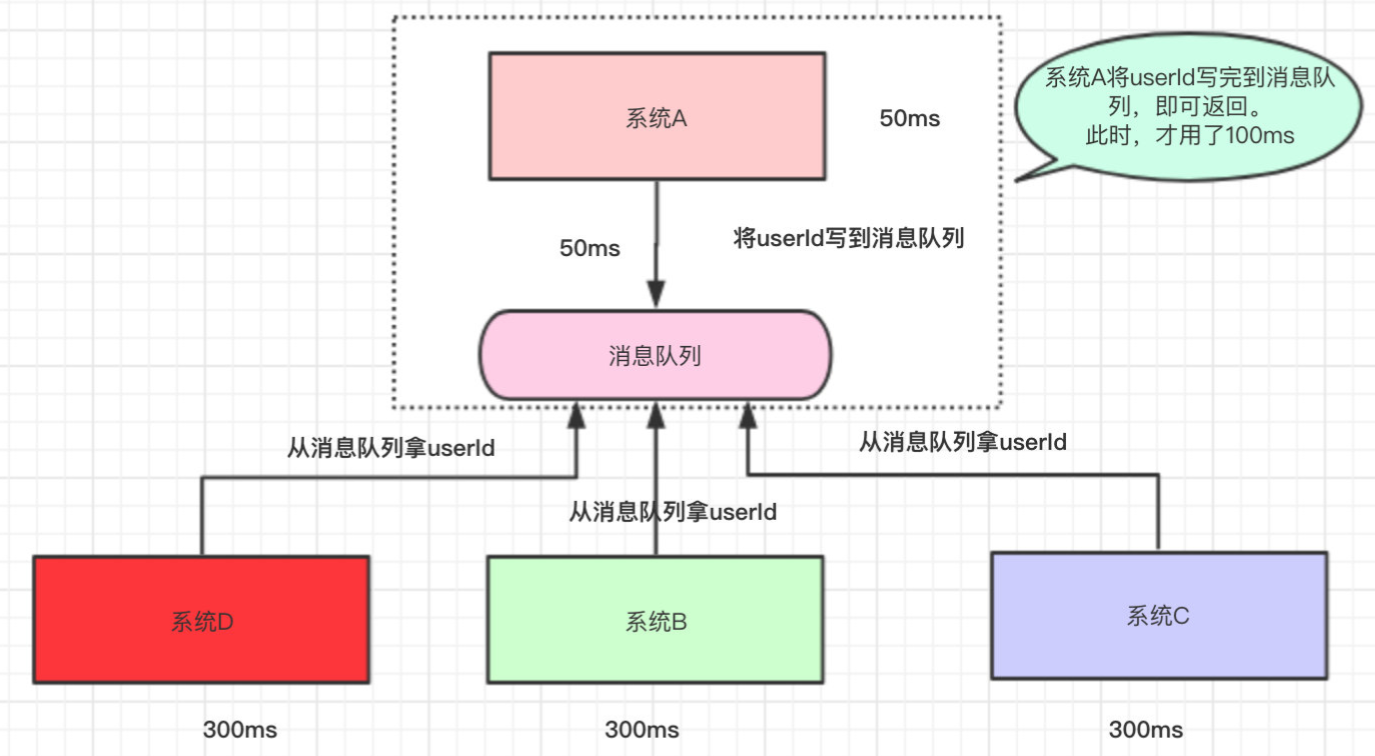
系统A执行完了以后,将 userId 写到消息队列中,然后就直接返回了(至于其他的操作,则异步处理)。
本来整个请求需要用950ms(同步),现在将调用其他系统接口异步化,只需要100ms(异步)
3.3 削峰/错流 – 消息缓存
场景:高并发场景 现在我们每个月要搞一次大促,大促期间的并发可能会很高的,比如每秒3000个请求。
假设我们现在有两台机器处理请求,并且每台机器只能每次处理1000个请求。
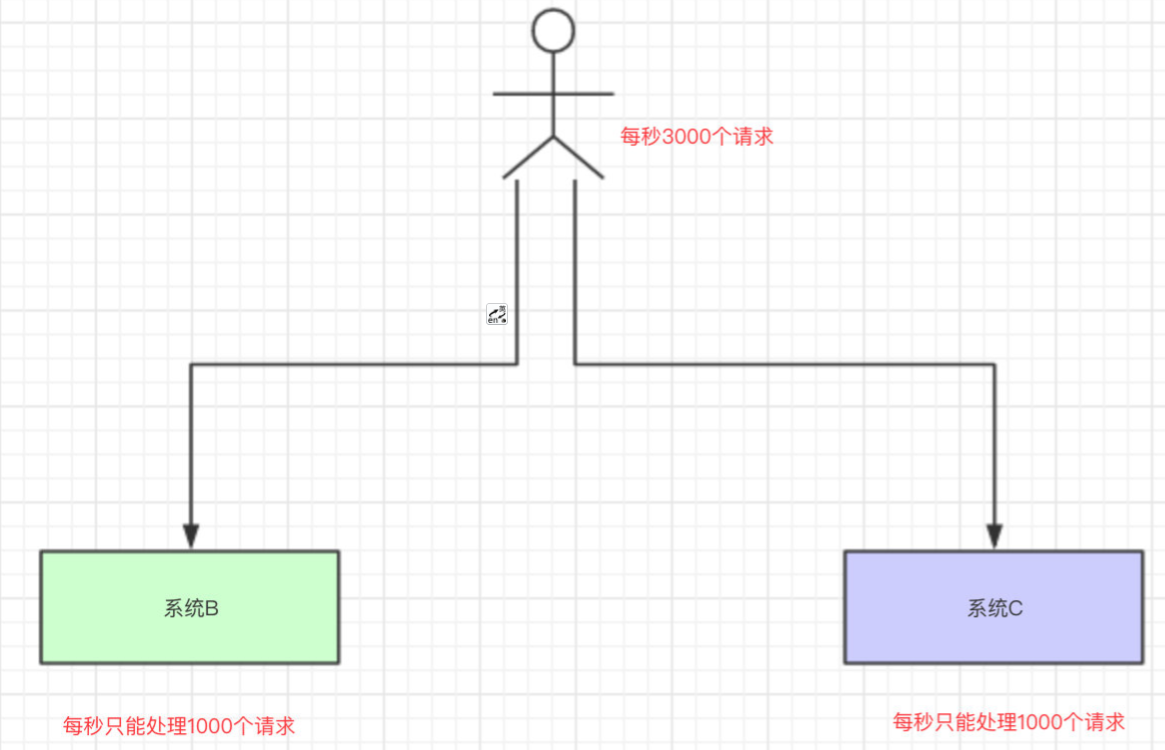
多出来的1000个请求,可能就把我们整个系统给搞崩了…所以,有一种办法,我们可以写到消息队列中
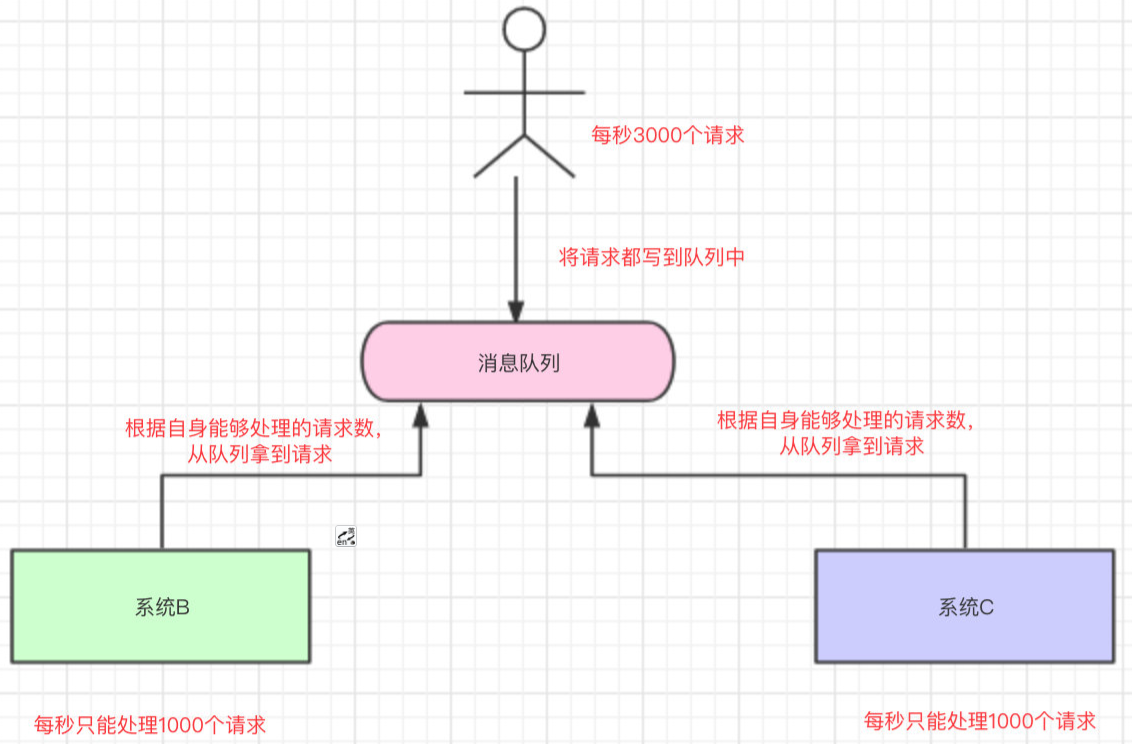
系统B和系统C根据自己的能够处理的请求数去消息队列中拿数据,这样即便有每秒有8000个请求,那只是把请求放在消息队列中,去拿消息队列的消息由系统自己去控制,这样就不会把整个系统给搞崩。
3.4 日志处理
指将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题
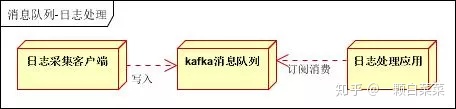
架构简化如下:
日志采集客户端 ==> 日志数据采集,定时写受写入Kafka队列
Kafka消息队列 ==> 负责日志数据的接收,存储和转发
日志处理应用 ==> 订阅并消费kafka队列中的日志数据
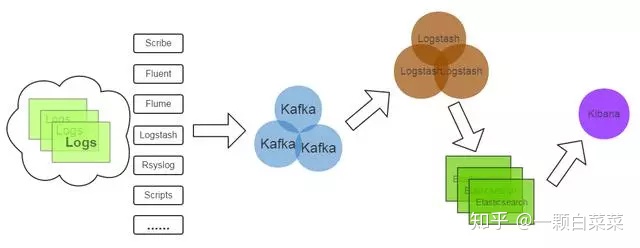
kafka 日志处理应用案例:
(1)Kafka:接收用户日志的消息队列
(2)Logstash:做日志解析,统一成JSON输出给 Elasticsearch
(3)Elasticsearch:实时日志分析服务的核心技术,一个schemaless,实时的数据存储服务,通过index组织数据,兼具强大的搜索和统计功能。
(4)Kibana:基于Elasticsearch的数据可视化组件,超强的数据可视化能力是众多公司选择ELK stack的重要原因
4.最终一致性
指的是两个系统的状态保持一致,一定时间后,要么都成功,要么都失败
[Notify(阿里)]
[QMQ(去哪儿)]
以上两MQ是专为最终一致性设计的,设计之初就是为了交易系统中的高可靠通知
银行的转账过程来理解最终一致性,转账的需求很简单,如果A系统扣钱成功,则B系统加钱一定成功
反之则一起回滚,像什么都没发生一样
意外:
A扣钱成功,调用B加钱接口失败
A扣钱成功,调用B加钱接口虽然成功,但获取最终结果时网络异常引起超时
A扣钱成功,B加钱失败,A想回滚扣的钱,但A机器down机 等
- 方案1:强一致性,分布式事务,但落地太难且成本太高
- 方案2:最终一致性,主要是用“记录”和“补偿”的方式
1.在做所有的不确定的事情之前,先把事情记录下来,然后去做不确定的事情 结果可能是:成功、失败或是不确定,“不确定”(例如超时等)可以等价为失败
成功就可以把记录的东西清理掉了
失败和不确定,可以依靠定时任务等方式把所有失败的事情重新搞一遍,直到成功为止
系统在A扣钱成功的情况下
把要给B“通知”这件事记录在库里
(为了保证最高的可靠性可以把通知B系统加钱和扣钱成功这两件事维护在一个本地事务里),
通知成功则删除这条记录,通知失败或不确定则依靠定时任务补偿性地通知我们,直到我们把状态更新成正确的为止。
整个这个模型依然可以基于RPC来做,但可以抽象成一个统一的模型,基于消息队列来做一个“企业总线”
本地事务维护业务变化和通知消息,一起落地(失败则一起回滚)
1)然后RPC到达broker,在broker成功落地后,RPC返回成功,本地消息可以删除
2)否则本地消息一直靠定时任务轮询不断重发,保证了消息可靠落地broker
最终一致性不是消息队列的必备特性,但确实可以依靠消息队列来做最终一致性的事情,所有不保证100%不丢消息的消息队列,理论上无法实现最终一致性。
好吧,应该说理论上的100%,排除系统严重故障和bug。
像Kafka一类的设计,在设计层面上就有丢消息的可能(比如定时刷盘,如果掉电就会丢消息),哪怕只丢千分之一的消息,业务也必须用其他的手段来保证结果正确。
电商下单经典案例,展现出解耦、异步、削峰/错流、日志处理等 MQ 应用
参考:
文档信息
- 本文作者:jiushun.cheng
- 本文链接:https://minipa.github.io/2019/06/13/mq-base/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)