
1.设计实现 一个MQ
MQ 本质
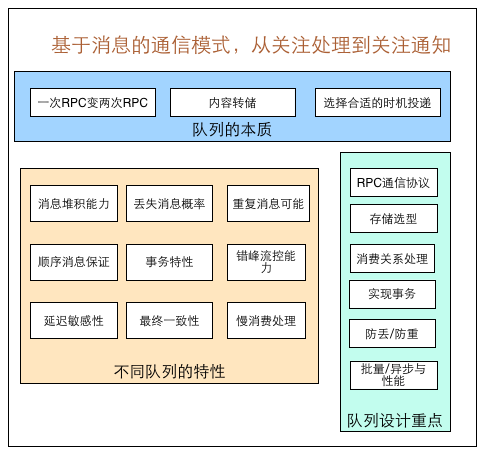
通信模式变更,基于消息通信 关注 处理 ==> 通知
1.一次 RPC 变二次 RPC
2.内容转储
3.选择合适时机投递
不同 MQ 队列特性
1.消息堆积能力、错峰流控能力、慢消费处理
2.消息丢失概率、消息重复可能性、消息顺序保证
3.事务特性、延迟敏感性、最终一致性
MQ 队列设计重点
1.RPC 通信协议
2.存储选型
3.消费关系处理
4.实现事务
5.防丢/防重
6.批量/异步与性能
2.MQ 基本功能
1.RPC 通信协议
MQ 消息队列 = RPC + 转储 + RPC + [RPC 消费方确认消费],两/三次 RPC 加一次转储。
RPC ==> 负载均衡啊、服务发现啊、通信协议啊、序列化协议啊,等等。==> Thrift Dubbo 等
服务端提供两个 RPC 服务,
RPC1 接收消息
RPC2 确认消息收到
做到不管哪个 server 收到消息和确认消息,结果一致即可,优先选择本机房投递
2.高可用
MQ高可用 = 依赖于RPC和存储的高可用
RPC 高可用,美团的基于MTThrift的RPC框架,阿里的Dubbo等,其本身就具有服务自动发现,负载均衡等功能。
MQ 的高可用,保证 broker 接受消息和确认消息的接口是幂等的,并且 consumer 的几台机器处理消息是幂等的,这样就把消息队列的可用性,转交给RPC框架来处理了。
保证幂等 ==> 共享存储来实现,broker 多机器共享一个DB 或者一个分布式文件/kv系统,处理消息是幂等的,也可防止单点故障问题。
failover 可以依赖定时任务的补偿,MQ本身实现支持此功能。
其它:不共享存储的队列如Kafka,使用分区加主备模式,需要保证每一个分区内的高可用性。
每一个分区至少要有一个主备且需要做数据的同步,可参考 pull模型 消息系统设计。
3.吞吐量:服务端承载消息堆积的能力
MQ 把消息存储下来,选择时机投递 ==> 存储方式 :内存、K/V、磁盘、DataBase里等
- 持久化:更好保证消息的可靠性(如断电等不可抗外力),能承载更大限度的消息堆积,磁盘比硬盘便宜。
- 非持久化:部分 Message 对性能要求大于可靠性,数量级高,如日志。
消息不落地直接暂存内存,尝试几次 failover,最终投递出去也行。
4.存储子系统
数据需要落地,存储子系统选择。
速度: 文件系统 > 分布式KV(持久化)> 分布式文件系统 > 数据库
可靠性:与上相反。
根据业务场景选择方案 ,单 broker 5位数以上QPS性能,基于文件存储比较好,DB 受限制于 IOPS。
整体上可以采用 数据文件+索引文件 的方式处理。
分布式KV(如 MongoDB,HBase)、持久化的 Redis,编程接口较友好,性能也比较可观,可靠性要求不高也可以选择。
5.消费关系解析 转储消息能力。
解析发送接收关系,正确投递
JMS 规范中的Topic/Queue
Kafka 的Topic/Partition/ConsumerGroup
RabbitMQ 的Exchange等等。
单播,点到点
广播,点对多点
互联网的大部分应用来说,组间广播、组内单播
消息要通知到多个业务集群,每个集群内很多台机器一台消费Message即可以了。
消费关系除了组内组间,可能会有多级树状关系,一般比较通用的设计是支持组间广播,不同的组注册不同的订阅
组内的不同机器
如果注册一个相同的ID,则单播
如果注册不同的ID(如IP地址+端口),则广播
广播关系的维护,一般由于消息队列本身都是集群,所以都维护在公共存储上,config server、zookeeper等。维护广播关系所要做的事情基本是一致的:
- 发送关系的维护
- 发送关系变更时的通知。
3.MQ 高级特性
1.可靠投递(最终一致性)
- 1)完全不丢消息 ==> 可能,前提是消息可能会重复,在异常情况下,要接受消息的延迟。
方案:每当要发生不可靠的事情(RPC等)之前,先将消息落地,然后发送
当失败或者不知道成功失败(比如超时)时,消息状态是待发送。定时任务不停轮询所有待发送消息,最终一定可以送达。
具体来说:producer 往 broker 发送消息之前,需要做一次落地。请求到 server 后,server 确保数据落地后再告诉客户端发送成功。
支持广播的消息队列需要对每个待发送的 endpoint,持久化一个发送状态,直到所有 endpoint 状态都OK才可删除消息。
消息未送达:
不确定因素:超时、宕机、断网、消息未送达、送达后数据没落地、数据落地了回复没收到 等很多不确定性
对于发送方来说,都是一件事情,就是消息没有送达。
重推消息 会有消息重复问题,重复和丢失要根据业务权衡考量。重复可再处理,丢失不好找回。及时重复可处理,也应该尽量减少重复。
结合业务,论坛、Blog等场景,重复消息有时比丢失更让用户难受。
2.消费确认
broker 将 Message 给到 Customer,Customer 进行响应,告诉 broker 已接收并处理了此消息。
接收是第1步,还需要处理,处理阶段也可能出现异常。
把 消息的送达 和 消息的处理 分开,这样才真正的实现了消息队列的本质 - 解耦。
1.在默认 Auto Ack 基础上,允许消费方主动 Ack 确认消费
2.消费结果:成功、拒绝、错误
reject 业务方无法感知 ==> 推演为 系统的流量、健康、性能评估非常重要,也非常复杂,可处理为滑动窗口/池化等模式。消费能力不匹配的时候,直接拒绝,过一段时间重发,减少业务的负担。
3.允许业务方主动 Ack 确认消费成功,如失败,可以约定处理后续处理方式,重复投递或警告异常。
3.重复、顺序消息
重复消息,不能100%避免,幂等处理,减少重复投递
顺序消息,可以100%避免,条件更苛刻
==> 绝对的顺序消息基本上是不能实现,除非允许消息丢失,从发送方到服务方到接受者都是单点单线程。
顺序方案:METAQ/Kafka等 pull模型 的消息队列中,单线程生产/消费,排除消息丢失,是一种顺序方案。
重复方案:
记录校验:broker 记录 MessageId,投递成功后清除,重复ID到来不做处理,发送者在清除周期内能够感知到消息投递成功,基本不会在 server端 产生重复消息。
询问:不确定消息目前是在被处理,还是已丢失等情况,记录投递IP,重发前询问比较靠谱。
4.pull push 模型的MQ 见单独篇章
5.sync / async 同步/异步 见单独篇章
6.batch 批量消息 见单独篇章
4.MQ 容易忽视的问题
1.系统复杂性
引入 MQ,代码中要考虑:消息重复、丢失、顺序消费等一系列问题
2.数据一致性
个人业务成功了,消息丢到 MQ成功了,后续N 服务要接着处理,那么这些处理成功与失败也是有一定必要管理的。
==> 这就是一致性问题 ==> 分布式事务
3.可用性
MQ 挂了呗,完了 N 服务系统都崩溃,这个在 MQ 选型的时候就要留意了。
RabbitMQ、ActiveMQ 舍弃、可参考。
Kafka、RocketMQ 各有所长。
==> 参考 MQ 选型篇章
参考:
文档信息
- 本文作者:jiushun.cheng
- 本文链接:https://minipa.github.io/2019/06/14/mq-advantage/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)