
Java核心技术 思维导图节点(Database -> Nosql -> mongodb)
一、Mongodb 介绍
1.面向集合, 模式自由的文档型数据库
- 基于分布式文件存储
- 数据具备自述性(self-describing),呈现分层的树状数据结构
- 数据结构由键值(key=>value)对组成
2.查询:独特的Mongodb的查询方式
- 平均插入速率:MongoDB不指定_id插入 > MySQL不指定主键插入> MySQL指定主键插入 > MongoDB指定_id插入
3.存储:虚拟内存+持久化
- 数据实际上是存放在硬盘的
- 所有要操作的数据通过mmap的方式映射到内存某个区域内
- MongoDB就在这块区域里面进行数据修改,避免了零碎的硬盘操作
适合:事件的记录、内容管理、博客平台等等 架构:可以通过副本集,以及分片来实现高可用
4.优劣势
- 优势
- 速度:适量级的内存的Mongodb的性能是非常迅速
- 高扩展性:副本集 + Sharding
- 高可用:副本 + Failover 机制
- 高效存储:存储格式是BJSON,Binary-JSON即序列化后的json
- 缺点
- 弱一致,不支持事务,开发文档也不是很完善
- 占用空间过大
5.Mongodb 与 Mysql
- 比对方式
- 数据模型:关系型/非关系型
- 存储方式:虚拟内存 + 持久化 / 不同引擎不同
- 架构特点:副本集+分片实现高课用 / M-S,MHA,MMM,Cluster等架构
- 数据处理:基于内存,热数据存在物理内存中 / 不同引擎不相同
二、Mongodb 关键技术介绍
1 DataModel 数据模型
- 1.Flexible Schema: 无需 Document 有固定提前设定的 Schema 格式
- 2.写操作原子性
- 单个文档写;操作具有原子性
- 多个文档写:整体不具有原子性 db.collection.updateMany())
Doc 文档结构
1.Embedded Data 嵌套数据 ==> Normalized 归一化数据结构
document 最大 16M字节,更大要用 GridFS 使用场景:
- 1)存在包含 “contains” 关系的实体,做成嵌套数据, one-to-one
- 2)存在 one-to-many 关系实体

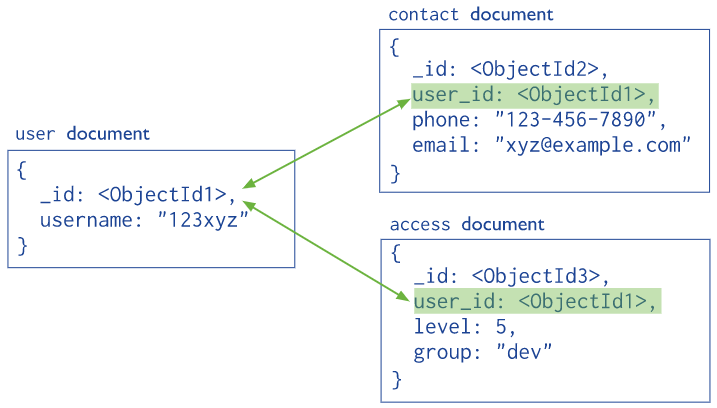
2.Reference Data 引用关联数据 ==> Denormalized 非规则化数据
使用场景:
- 1)嵌套会导致数据重复,但又不能提供足够的读取优势超高重复的影响时,用引用
- 2)many-to-many 关系数据
- 3)对大型分层数据,进行建模 聚合函数
- $lookup (Available starting in MongoDB 3.2)
- $graphLookup (Available starting in MongoDB 3.4)
BSON
-[ ] TODO
2.index 索引
Index: 索引是特殊的数据结构
以易于遍历的形式存储集合数据集的一小部分
索引存储特定字段或一组字段的值,按字段值排序
索引条目的排序支持高效的相等匹配和基于范围的查询操作
此外,MongoDB 可以使用索引中的排序返回排序结果
_id 默认唯一索引
分片集群中,不用_id分片,就得自己保证分片唯一性,经常会用自动生成的 ObjectId
B-tree data structure 作为 mongodb 的索引
Index 属性
- Unique: 唯一
- Partial: 部分索引,仅对满足过滤条件的文档进行索引
- Spare: 稀疏索引,确保只索引包含索引字段的文档
- TTL: 超时索引,超时自动删除文档,如事件、日志等记录
- Hidden: 隐藏索引,对查询计划不可见,不支持查询优化,可以在不实际删除索引情况下,评估删除索引的影响除了 _id 索引,其他索引均可隐藏
Index 类型
- 1.Single Field: 支持排序
- 2.Compound Index 联合索引
- 3.Multikey Index 多键索引
- Geospatial Index 地理位置信息索引
- Text Indexes 问本索引,支持问本检测
- Hashed Indexes 哈希索引,支持hash为基础的分片
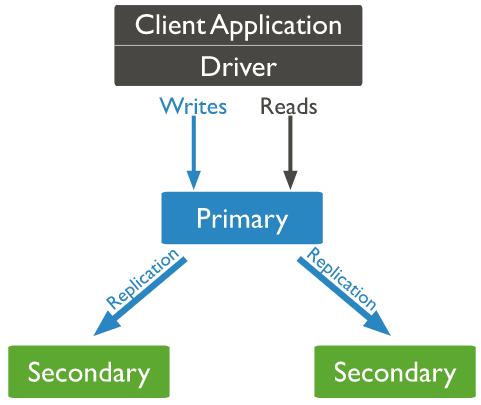
3.副本和分片
replication 副本
sharding 分片
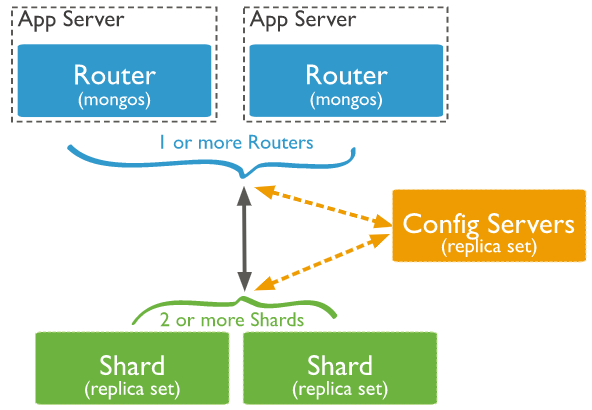
4.Store 存储
1.WiredTiger Storage Engine (Default) 提供
- 1)文档级并发模型 Document Level Concurrency、
- 2)检查点 Snapshots And Checkpoints
- 3)压缩 Compresssion 等功能 zlib、zstd ```html Journal: write-ahead log, 预写日志 结合 检查点 确保数据持久性 使用 snappy 压缩 journal 文件 storage.journal.enabled = false
Memory Use: MongoDB 同时使用 WiredTiger 内部缓存和文件系统缓存
#### 2.In-Memory Storage Engine: 企业级可用,内存存储,提供更可预测的数据延迟
```html
mongod --storageEngine inMemory --dbpath <path>
storage:
engine: inMemory
dbPath: <path>
1.写操作 文档级并发保证
storage:
engine: inMemory
dbPath: <path>
inMemory:
engineConfig:
inMemorySizeGB: <newSize>
2.持久化 Durability
日志或等待数据变得持久的概念不适用于内存存储引擎
如果副本集的任何投票成员使用内存存储引擎,则必须将 writeConcernMajorityJournalDefault 设置为 false
3.transactions
主节点使用 WiredTiger 存储引擎,并且次要成员使用 WiredTiger 存储引擎或内存存储引擎
只有使用 WiredTiger 存储引擎的副本集支持事务
文档信息
- 本文作者:jiushun.cheng
- 本文链接:https://minipa.github.io/2021/07/28/mongodb/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)