
Java核心技术 思维导图节点(Database -> Nosql -> ES)
一、ElasticSearch 介绍
1.ES 定义
分布式、RESTful 风格的搜索和数据分析引擎
- 分布式的实时文档存储,每个字段 可以被索引与搜索
- 分布式实时分析搜索引擎
- 胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
2.ES 用途
- 1.定义自己的 搜索方式: 执行及合并多种类型的搜索 (结构化数据、非结构化数据、地理位置、指标),搜索方式随心而变
- 2.分析大规模数据:面对10亿行数据
3.ES 特点
- 1.快速获得结果,会使得人和数据关系发生质的改变
- 2.全文检索、倒排索引,实现全文检索,实现了用于存储数值数据和地理位置数据的 BKD 树,以及用于分析的列存储
- 3.无所不包:每个数据都被编入了索引
- 4.RestFul 风格API 和 JSON
- 5.序列化格式:JSON
二、ElasticeSearch 技术核心要点
1._score ES 相关度算法
_score 评分越高、相关性越高
- fuzzy: 计算与关键词的拼写相似度
- terms: 计算找到的内容与关键词组成部分匹配的百分比
- relevance: 通常指用来计算全文本字段的值相对于全文本检索词相似程度的算法
ES 相似度算法 ==> 检索词频率/反向文档频率, TF/IDF
TF 检索词频率: 检索词在该字段出现的频率?出现频率越高,相关性也越高。 字段中出现过 5 次要比只出现过 1 次的相关性高
IDF 反向文档频率: 每个检索词在索引中出现的频率? 频率越高,相关性越低。 检索词出现在多数文档中会比出现在少数文档中的权重更低
字段长度准则: 字段的长度是多少?长度越长,相关性越低。 检索词出现在一个短的 title 要比同样的词出现在一个长的 content 字段权重更大
[explain 产生分数] format=yaml 加上参数转 yaml 更好阅读
"_explanation": { # 计算总结
"description": "weight(tweet:honeymoon in 0)
[PerFieldSimilarity], result of:",
"value": 0.076713204,
"details": [
{
"description": "fieldWeight in 0, product of:",
"value": 0.076713204,
"details": [
{
"description": "tf(freq=1.0), with freq of:", # TF 检索词评率
"value": 1,
"details": [
{
"description": "termFreq=1.0",
"value": 1
}
]
},
{
"description": "idf(docFreq=1, maxDocs=1)", # IDF 反向文档评率
"value": 0.30685282
},
{
"description": "fieldNorm(doc=0)", # 字段长度准则
"value": 0.25,
}
]
}
]
}
GET /us/tweet/12/_explain
{
"query" : {
"bool" : {
"filter" : { "term" : { "user_id" : 2 }},
"must" : { "match" : { "tweet" : "honeymoon" }}
}
}
}
2.sort: Doc Values 为排序存储转置的倒排索引
- [背景] 倒排索引的检索性能是非常快的,但是在字段值排序时却不是理想的结构 ```html 在搜索的时候,我们能通过搜索关键词快速得到结果集
当排序的时候,我们需要倒排索引里面某个字段值的集合,换句话说,我们需要 转置 倒排索引
转置 结构在其他系统中经常被称作 列存储
- Doc Values 列存储
它将所有单字段的值存储在单数据列中,这使得对其进行操作是十分高效的,例如排序
- 对一个字段进行排序
- 对一个字段进行聚合
- 某些过滤,比如地理位置过滤
- 某些与字段相关的脚本计算
```json
"docvalue_fields": [
{
"field": "@timestamp",
"format": "date_time"
},
{
"field": "data.createTime",
"format": "date_time"
},
{
"field": "data.updateTime",
"format": "date_time"
}
]
3.version conflict 版本冲突
3.1 背景:如下图
web_1 对 stock_count 所做的更改已经丢失,因为 web_2 不知道它的 stock_count 的拷贝已经过期。变更越频繁,读数据和更新数据的间隙越长,也就越可能丢失变更 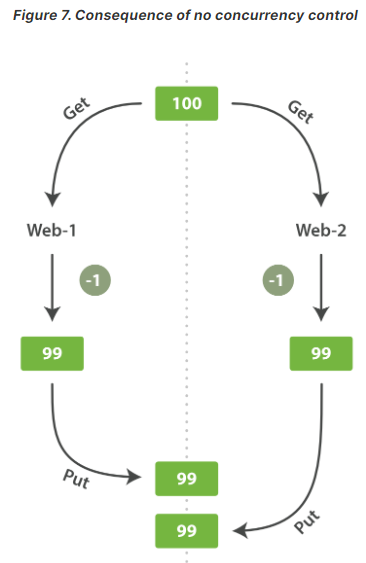
3.2 处理方案
悲观并发控制:被关系型数据库广泛使用
它假定有变更冲突可能发生,因此阻塞访问资源以防止冲突 一个典型的例子是读取一行数据之前先将其锁住,确保只有放置锁的线程能够对这行数据进行修改
乐观并发控制:Elasticsearch 中使用
- 假定冲突是不可能发生的,并且不会阻塞正在尝试的操作,如果源数据在读写当中被修改,更新将会失败
- 应用程序接下来将决定该如何解决冲突,例如,可以重试更新、使用新的数据、或者将相关情况报告给用户
1.背景:ES是异步、并发的,_version 保证有序、数据不丢失
索引请求,指定 _version 老版本
# 返回 409 Conflict HTTP
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[blog][1]: version conflict, current [2], provided [1]",
"index": "website",
"shard": "3"
}
],
"type": "version_conflict_engine_exception",
"reason": "[blog][1]: version conflict, current [2], provided [1]",
"index": "website",
"shard": "3"
},
"status": 409
}
外部系统方案
其它数据库作为主要的数据存储,使用 Elasticsearch 做数据检索
# 创建一个新的具有外部版本号 5 的博客文章
PUT /website/blog/2?version=5&version_type=external
{
"title": "My first external blog entry",
"text": "Starting to get the hang of this..."
}
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_version": 5,
"created": true
}
# 更新这个文档,指定一个新的 version 号是 10
PUT /website/blog/2?version=10&version_type=external
{
"title": "My first external blog entry",
"text": "This is a piece of cake..."
}
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_version": 10,
"created": false
}
指定的外部版本号不大于 Elasticsearch 的当前版本号,会返回失败
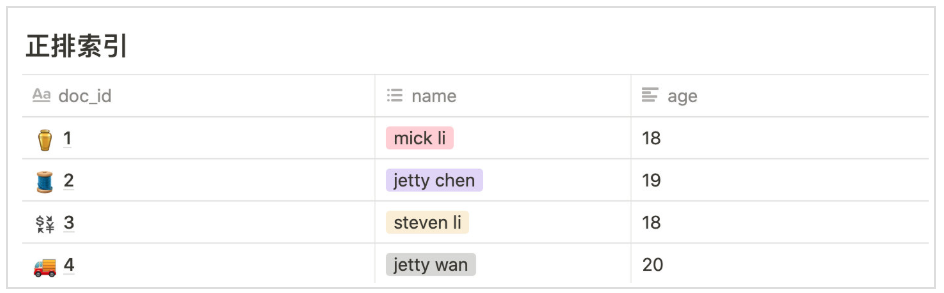
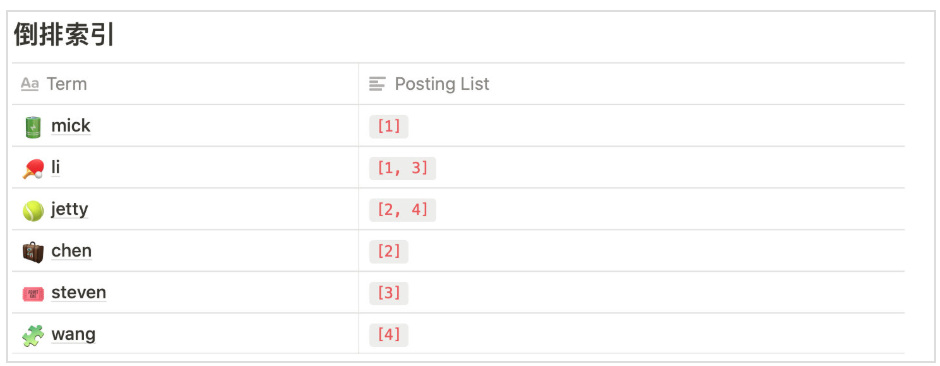
4.倒排索引
4.1.基于 lucence 全文检索
对数据分词保存索引,擅长管理大量索引数据,不擅长经常更新数据,及关联查询 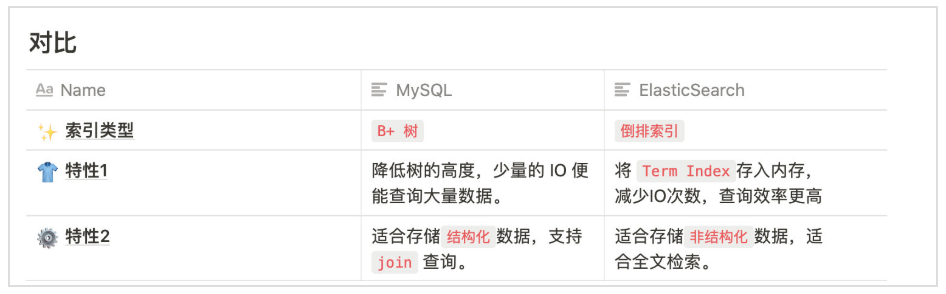
4.2 ES高效原因
- 倒排索引,分词: 1)分词 2)分词文档表 ==> 文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表
- BitMap
二、ElasticSearch 集群原理
四、ES 核心概念(梳理下自己的理解)
1.data 数据出入
1.1 文档元数据
- _index 索引:文档在哪存放,数据存放 逻辑命名空间,实际是多个分片存放数据;名字必须小写,不能以下划线开头,不能包含逗号
- _type 文档表示的对象类别,在索引中对数据进行逻辑分区,可以是大写或者小写,但是不能以下划线或者句号开头,不应该包含逗号,并且长度限制为256个字符
- _id 文档唯一标识
1.2 文档操作关键词
pretty
_source=title,text
_bulk _mget
_create
_update retry_on_conflict=5
_delete
- _update: 从旧文档构建 JSON,更改该 JSON,删除旧文档,索引一个新文档
2.index 索引 检索
2.1 索引(插入): 数据存到 ES 的行为,保存数据的地方
- 索引 -> 类型 -> 文档 -> 属性
- 索引实际是指向一个/多个 物理分片的逻辑命名空间
PUT /megacorp/employee/1 { "first_name" : "John", "last_name" : "Smith", "age" : 25, "about" : "I love to go rock climbing", "interests": [ "sports", "music" ] } - 添加索引
PUT /blogs { "settings" : { "number_of_shards" : 3, "number_of_replicas" : 1 } }2.2 检索(查询):获取索引内容
GET /megacorp/employee/1 # 返回原始的 JSON 文档 { "_index" : "megacorp", # 索引 "_type" : "employee", # 类型 "_id" : "1", # 文档ID 等 "_version" : 1, "found" : true, "_source" : { "first_name" : "John", "last_name" : "Smith", "age" : 25, "about" : "I love to go rock climbing", "interests": [ "sports", "music" ] } } - _search 检索关键响应
_score: 文档与查询的匹配程度,降序排列 took: 请求耗时 shards: 参与查询分片数 timeout: 超时 GET /_search?timeout=10ms - 分页: size=5&from=5
2.3 Filter 和 Query
- Filter: 不评分,只准确过滤,会被缓存
- Query: 评分相关性查询,不会被缓存
2.5 关键 Keys
- match 标准查询,无论全文搜索、精确查询 ==> 全文检索,在执行查询前,会用正确得分析器分析查询字段
- multi_match 可以在多个字段上执行相同的 match 查询
- range 定区间内的数字或者时间
- term 精确值匹配,这些精确值可能是数字、时间、布尔或者那些 not_analyzed 的字符串,对于输入的文本不分析,所以它将给定的值进行精确查询
- terms 多值精确匹配
- exists missing 查询被用于查找那些指定字段中有值 (exists) 或无值 (missing) 的文档
- match_phrase 短语搜索,精确匹配一系列单词或者_短语
- must: 必须
- must_not: 必须不匹配
- should 满足则增加 _score, 否则无任何影响,主要用于修正文档相关得分
- filter 必须匹配,以不以评分、过滤模式处理,对评分没有贡献,只用来排除文档
- constant_score 常量评分
- _validate 验证查询是否合法
- explain # explain 理解错误信息
- sort 按照字段的值排序
2.6 DSL 表达式搜索
- 叶子语句(Leaf clauses) (就像 match 语句) 被用于将查询字符串和一个字段(或者多个字段)对比
- 复合(Compound) 语句 主要用于 合并其它查询语句 ==> 复合语句之间可以互相嵌套,可以表达非常复杂的逻辑
- 一个 bool 语句 允许在你需要的时候组合其它语句, 无论是 must 匹配、 must_not 匹配还是 should 匹配,同时它可以包含不评分的过滤器(filters) ```json
过滤下 年龄>30
GET /megacorp/employee/_search { “query” : { “bool”: { “must”: { # must 必须全匹配 “match” : { “last_name” : “smith” # must match “smith” } }, “filter”: { “range” : { “age” : { “gt” : 30 } # filter range gt } } } } }
复合查询
{ “bool”: { “must”: { “match”: { “tweet”: “elasticsearch” }}, “must_not”: { “match”: { “name”: “mary” }}, “should”: { “match”: { “tweet”: “full text” }}, “filter”: { “range”: { “age” : { “gt” : 30 }} } } }
- highlight 高亮搜索
- aggs 基于数据生成一些精细的分析结果
- scroll 游标查询
### 3.map 映射和分析
#### 3.1 Elasticsearch 是如何解释我们文档结构的
```html
GET /gb/_mapping/tweet
{
"gb": {
"mappings": {
"tweet": {
"properties": {
"date": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
},
"name": {
"type": "string"
},
"tweet": {
"type": "string"
},
"user_id": {
"type": "long"
}
}
}
}
}
}
# 基于对字段类型的猜测, ES 动态为我们产生了一个映射
# date 字段被认为是 date 类型的,由于 _all 是默认字段,所以没有提及它
- _all 所有字段的值拼接成一个大的字符串,作为 _all 字段进行索引
3.2 精确值 vs 全文
- 精确值:很容易查询
- 全文:问本数据,通常只人类识别的语言书写 ```html 搜索 UK ,会返回包含 United Kindom 的文档
搜索 jump ,会匹配 jumped , jumps , jumping ,甚至是 leap
搜索 johnny walker 会匹配 Johnnie Walker , johnnie depp 应该匹配 Johnny Depp
fox news hunting 应该返回福克斯新闻( Foxs News )中关于狩猎的故事,同时, fox hunting news 应该返回关于猎狐的故事
#### 3.3 _analyze 分析器
##### 分析
将一块文本分成适合于倒排索引的独立的词条 分词
将这些词条统一化为标准格式以提高它们的“可搜索性”,或者 recall
##### 分析器
- 1.字符过滤器: 字符串按顺序通过每个 字符过滤器,在分词前整理字符串
- 2.分词器: 字符串被 分词器 分为单个的词条,简单的分词器遇到空格和标点的时候,可能会将文本拆分成词条
- 3.token 过滤器: 词条按顺序通过每个 token 过滤器
```html
这个过程可能会
改变词条(例如,小写化 Quick )
删除词条(例如, 像 a, and, the 等无用词)
增加词条(例如,像 jump 和 leap 这种同义词)
ES 提供了开箱即用的字符过滤器、分词器和token 过滤器
####### 内置分析器
eg."Set the shape to semi-transparent by calling set_trans(5)"
1.标准分析器: 根据 Unicode 联盟 定义的 单词边界 划分文本。删除绝大部分标点。最后,将词条小写
set, the, shape, to, semi, transparent, by, calling, set_trans, 5
2.简单分析器: 在任何不是字母的地方分隔文本,将词条小写
set, the, shape, to, semi, transparent, by, calling, set, trans
3.空格分析器: 在空格的地方划分文本
Set, the, shape, to, semi-transparent, by, calling, set_trans(5)
4.语言分析器:
可以考虑指定语言的特点
set, shape, semi, transpar, call, set_tran, 5
####### 使用分析器 索引一个文档时,它的全文域被分析成词条以用来创建倒排索引
在全文域 搜索 的时候,我们需要将查询字符串通过 相同的分析过程 ,以保证我们搜索的词条格式与索引中的词条格式一致
# 测试分析器
GET /_analyze
{
"analyzer": "standard",
"text": "Text to analyze"
}
# 响应结果
{
"tokens": [
{
"token": "text",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "to",
"start_offset": 5,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "analyze",
"start_offset": 8,
"end_offset": 15,
"type": "<ALPHANUM>",
"position": 3
}
]
}
3.4 _mapping 映射
1.核心域简单类型
字符串: string
整数 : byte, short, integer, long
浮点数: float, double
布尔型: boolean
日期: date
2.获取映射
# GET /gb/_mapping/tweet
{
"gb": {
"mappings": {
"tweet": {
"properties": {
"date": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
},
"name": {
"type": "string"
},
"tweet": {
"type": "string"
},
"user_id": {
"type": "long"
}
}
}
}
}
}
index 属性控制怎样索引字符串
analyzed 首先分析字符串,然后索引它。换句话说,以全文索引这个域
not_analyzed 索引这个域,所以它能够被搜索,但索引的是精确值。不会对它进行分析
no 不索引这个域。这个域不会被搜索到
string 域 index 属性默认是 analyzed
如果我们想映射这个字段为一个精确值,我们需要设置它为 not_analyzed
{
"tag": {
"type": "string",
"index": "not_analyzed"
}
}
analyzed 字符串域,定在搜索和索引时使用的分析器
{
"tweet": {
"type": "string",
"analyzer": "english"
}
}
3.5 复杂核心域类型
- 1.多值域
{ "tag": [ "search", "nosql" ]}数组中所有的值必须是相同数据类型的,ES 会用数组中第一个值的数据类型作为这个域的 类型
- 2.空域 下面三种域被认为是空的,它们将不会被索引
"null_value": null, "empty_array": [], "array_with_null_value": [ null ] 3.多层级对象
- 4.内部对象如何索引
ohters TODO
文档信息
- 本文作者:jiushun.cheng
- 本文链接:https://minipa.github.io/2021/08/06/01-elasticsearch/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)